1024程序员节
python快速入门
安卓分区
时间复杂度
sqoop
ArrayDeque
Terminal
two sum
端口号
kudu读写流程
函数模板
网站漏洞修复
基本指令
pthread
手机浏览器
高校失物招领系统
时间
IO流中的属性集
junit
OpenHarmony
RLHF
2024/4/14 12:50:01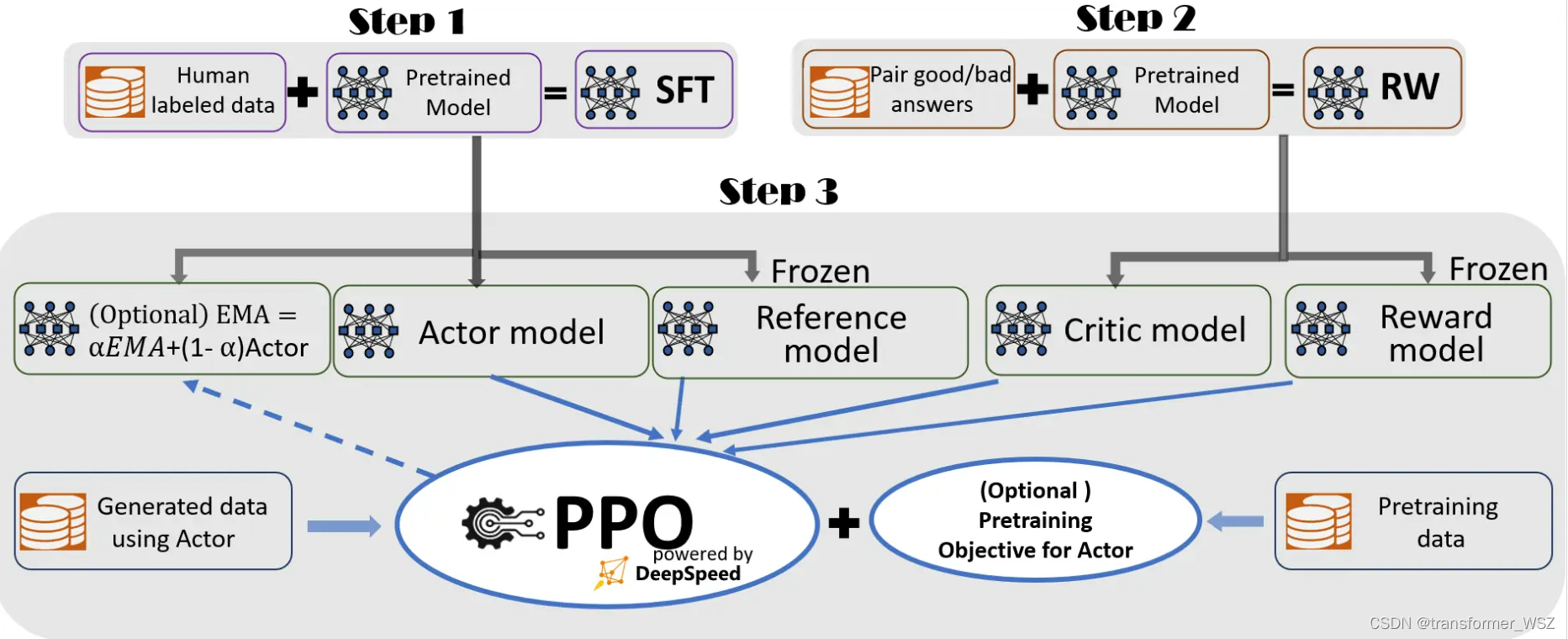
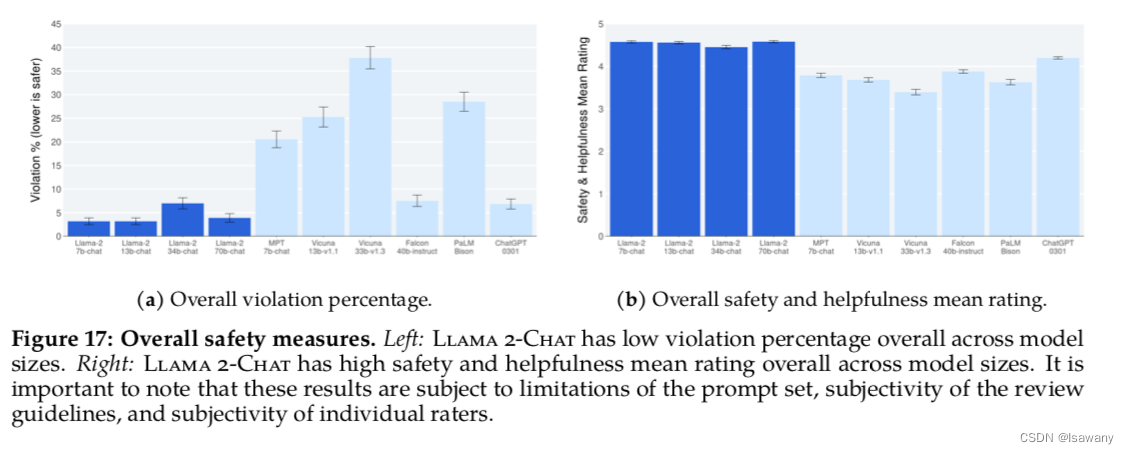
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…
使用Huggingface创建大语言模型RLHF训练流程的完整教程
ChatGPT已经成为家喻户晓的名字,而大语言模型在ChatGPT刺激下也得到了快速发展,这使得我们可以基于这些技术来改进我们的业务。
但是大语言模型像所有机器/深度学习模型一样,从数据中学习。因此也会有garbage in garbage out的规则。也就是说…

多模态大模型:关于RLHF那些事儿
Overview 多模态大模型关于RLHF的代表性文章一、LLaVA-RLHF二、RLHF-V三、SILKIE多模态大模型关于RLHF的代表性文章
一、LLaVA-RLHF
题目: ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF 机构:UC伯克利 论文: https://arxiv.org/pdf/2309.14525.pdf 代码…

文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
文献阅读:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback 1. 文章简介2. 方法介绍 1. 整体方法说明 3. 实验结果 1. RLHF vs RLAIF2. Prompt的影响3. Self-Consistency4. Labeler Size的影响5. 标注数据的影响 4. 总结 & 思考 文…
【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架
一个理解人类偏好学习的统一理论框架 《A General Theoretical Paradiam to Understand Learning from Human Preferences》 论文地址:https://arxiv.org/pdf/2310.12036.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框…
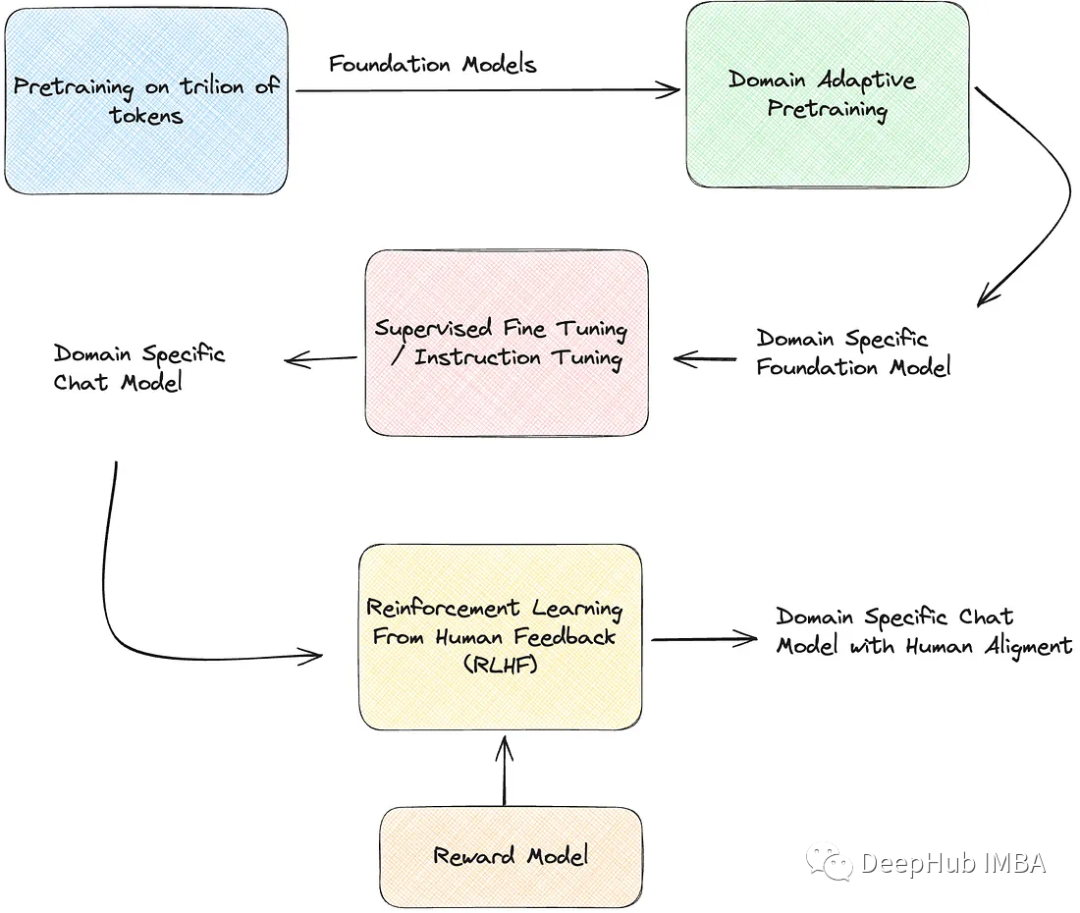
大语言模型微调和PEFT高效微调
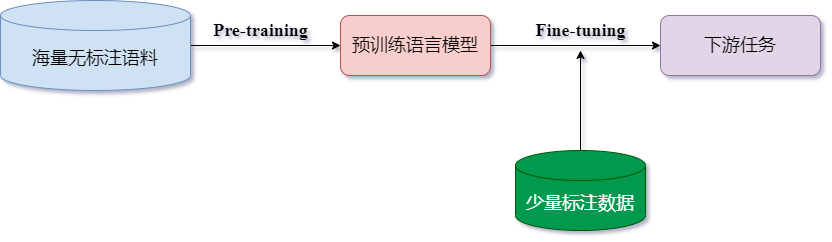
目录标题 1 解释说明1.1 预训练阶段1.2 微调阶段2 几种微调算法2.1 在线微调2.2 高效微调2.2.1 RLHF2.2.2 LoRA2.2.3 Prefix Tuning2.2.4 Prompt Tuning2.2.5 P-Tuning v21 解释说明 预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一…
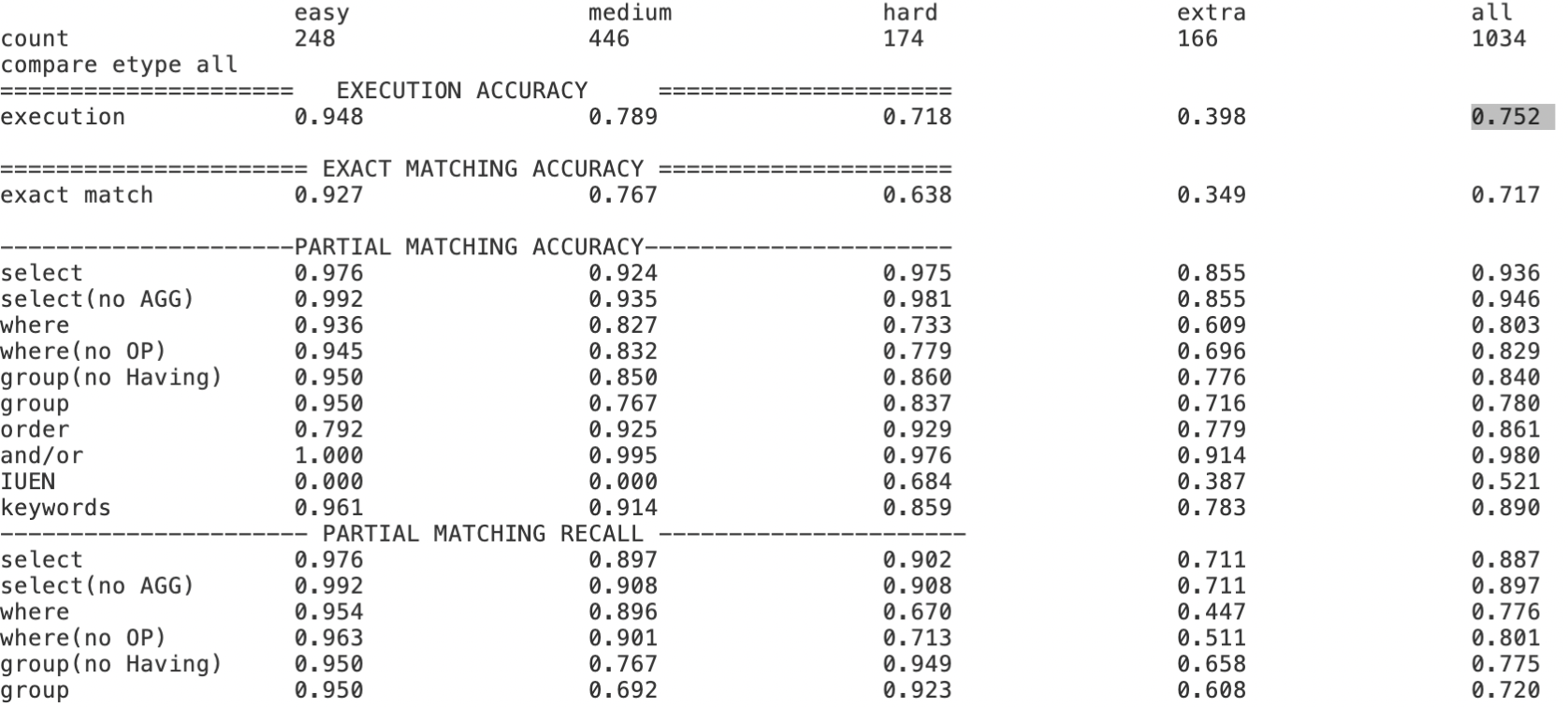
Text-to-SQL小白入门(十)RLHF在Text2SQL领域的探索实践
本文内容主要基于以下开源项目探索实践, Awesome-Text2SQL:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, Text2DSL、Text2API、Text2Vis and more.DB-GPT-Hub:GitHub - eosphoros-ai…
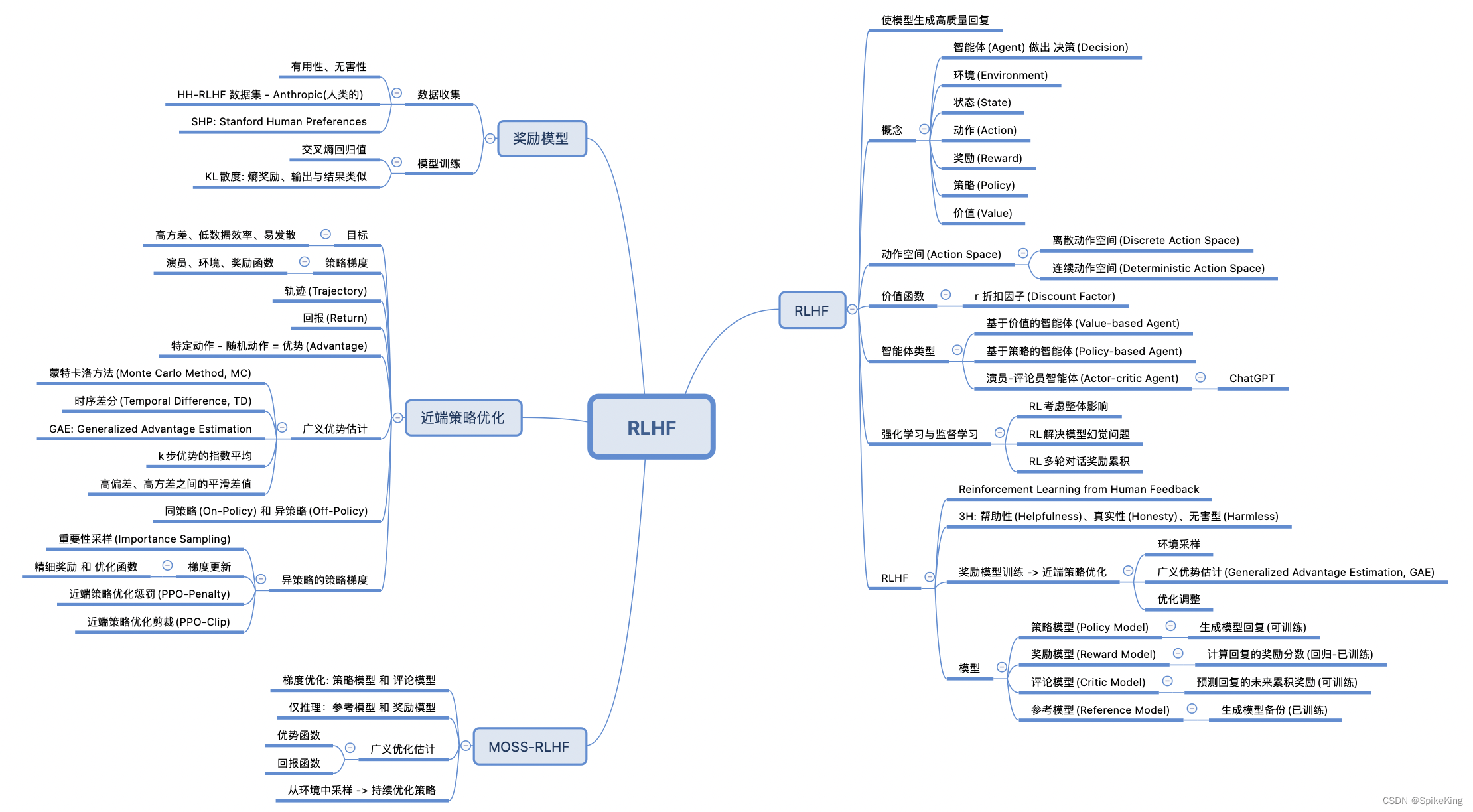
LLM - 大语言模型 基于人类反馈的强化学习(RLHF)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137269049 基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback),结合 强化学习(RL) 和 人类反馈 来优化模型的性能。这种方法主要包…
一文打通RLHF的来龙去脉
文章目录 1. RLHF的发展历程2. 强化学习2.1 强化学习基本概念2.2 强化学习分类2.3 Policy Gradient2.3.1 add a baseline2.3.2 assign suitable credit2.4 TRPO和PPO算法2.4.1 on-policy2.4.2 Important Sampling2.4.3 Off Policy2.4.4 TRPO 和 PPO 算法2.4.5 P
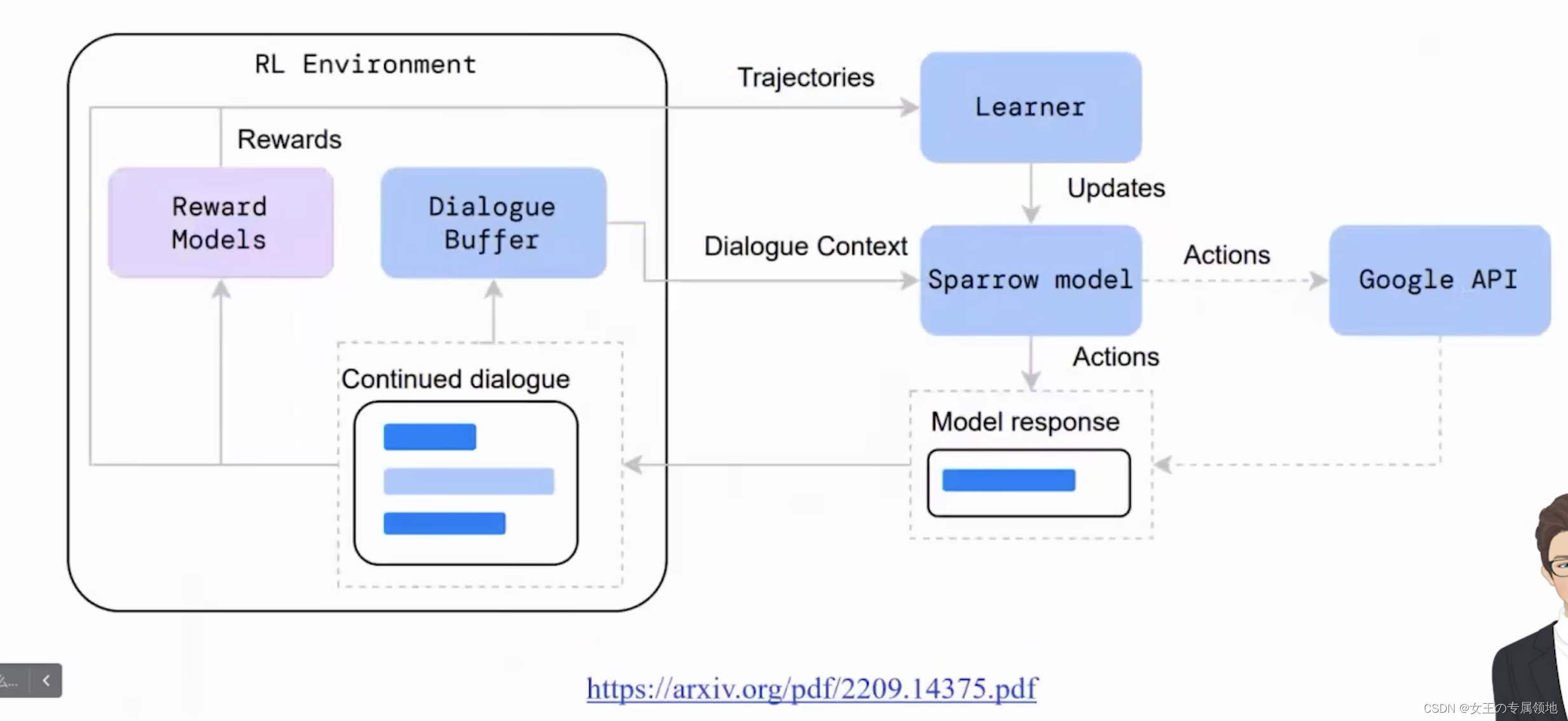
一文读懂「RLHF,Reinforcement Learning from Human Feedback」基于人类反馈的进行强化学习
一、背景由来
过去几年里,以ChatGPT为代表的基于prompt范式的大型语言模型 (Large Language Model,LLM) 取得了巨大的成功。然而,对生成结果的评估是主观和依赖上下文的,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和…

强化学习在文生图中的应用:Training Diffusion Models with Reinforcement Learning
论文链接:Training Diffusion Models with Reinforcement Learning项目地址:Training Diffusion Models with Reinforcement Learning官方代码:https://github.com/kvablack/ddpo-pytorch/tree/maintrl实现:https://huggingface.co/docs/trl/ddpo_trainer🤗关注公众号 fu…

【强化学习】PPO:近端策略优化算法
近端策略优化算法 《Proximal Policy Optimization Algorithms》 论文地址:https://arxiv.org/pdf/1707.06347.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架 【强化学习】PPO:近端策略优化算法 一、 置…

基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
Reinforcement Learning from Human Feedback
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
课程地址:https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/
Topic:
Get a conceptual understanding of Reinforcemen…
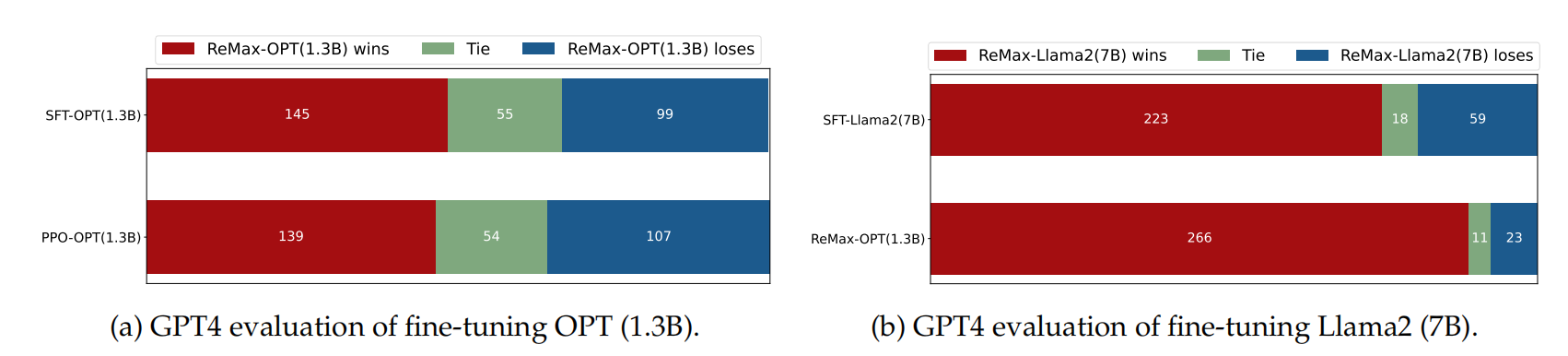
【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note
SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量…
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)。 MedicalGPT: Training Your Own Medical GPT Model with ChatGPT Training Pipeline. 训练医疗大模型,实现了包括增量预训练、有监督微…

GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT&#x…

《强化学习:原理与Python实战》——可曾听闻RLHF
前言: RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)是一种基于强化学习的算法,通过结合人类专家的知识和经验来优化智能体的学习效果。它不仅考虑智能体的行为奖励,还融合了人类专家…

大规模语言模型人类反馈对齐--RLHF
大规模语言模型在进行监督微调后, 模型具备了遵循指令和多轮对话的能力, 具备了初步与用户进行对话 的能力。然而, 大规模语言模由于庞大的参数量和训练语料, 其复杂性往往难以理解和预测。当这些模型被部署 时, 它们可…
通往AGI的大模型MultiAgent的RL是对的但HF有上限
OpenAI高管Mira Murati周三告诉员工,一封关于AI取得突破的信件促使董事会采取了解雇行动。一位消息人士透露,OpenAI在Q*项目上取得了进展,内部人士认为这可能是OpenAI在超级智能领域的突破。这名消息人士称,虽然Q*的数学成绩只是小…