python
jvm
FreeRTOS
经验
shell
云笔记
课程设计
渲染
PCB
AOE网
r语言
博通蓝牙使能
Thread Pool
图卷积神经网络
tokenizer
同步锁
risc-v
字节打印流
storageEvent
队列
embedding
2024/4/13 1:26:57
Stable Diffusion - 人物坐姿 (Sitting) 的提示词组合 与 LoRA 和 Embeddings 配置
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132201960 拍摄人物坐姿时,需要注意:
选择一个舒适和自然的坐姿,符合个性和心情。可以坐在椅子、沙发、长凳、…
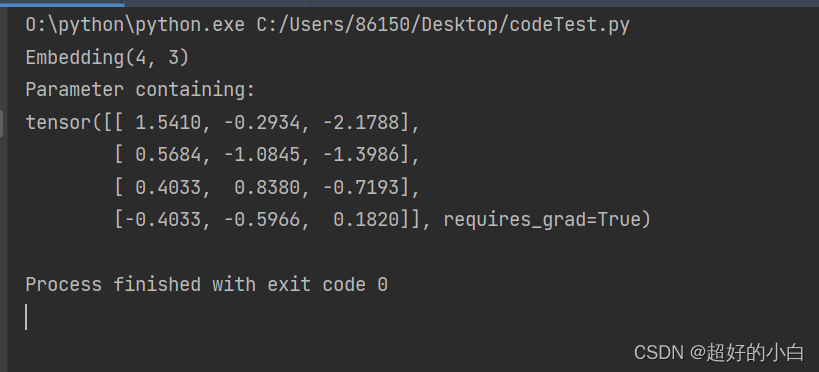
【学习】PyTorch中的nn.Embedding的用法
基本理解
nn.Embedding(num_embeddings, embedding_dim)其中 num_embeddings 是词表的大小,即 len(vocab);embedding_dim 是词向量的维度。
nn.Embedding()产生一个权重矩阵weight,其shape为(num_embeddings, embedding_dim&…

TensorFlow-Keras 9.基础文本处理 processing embedding
一.引言:
处理 IMDB 数据集 demo 时,用到了很多文本转 onehot,文本转 embedding 的方法,下面整理一下。
本文后续样例测试数据集采用 IMDB 原始数据集,代表了用户对电影的评价,其中包含积极 positive 以及 消极 naga…
OpenAI:ChatGPT API 文档之 Embedding
在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称为嵌入空间(embedding space),而生成的向量则称为嵌入向量(embedding vector࿰…
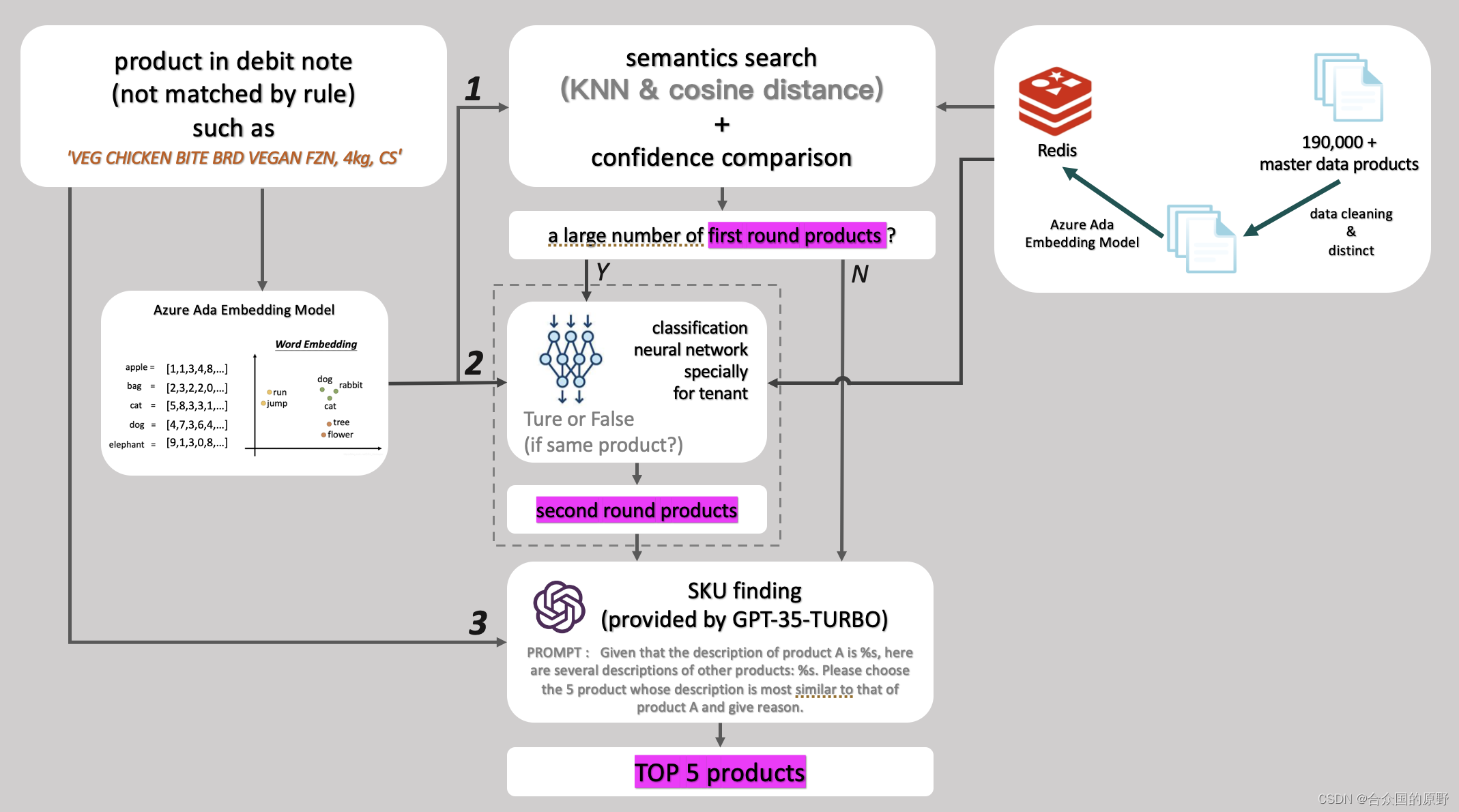
基于ChatGPT+词向量/词嵌入实现相似商品推荐系统
最近一个项目有个业务场景是相似商品推荐,给一个商品描述(比如 WIENER A/B 7IN 5/LB FZN ),系统给出商品库中最相似的TOP 5种商品,这种单纯的推荐系统用词向量就可以实现,不过,这个项目特点是商品库巨大,有…
Embedding压缩之基于二进制码的Hash Embedding
推荐系统中,ID类特征的表示学习(embedding learning)是深度学习模型成功的关键,因为这些embedding参数占据模型的大部分体积。这些模型标准的做法是为每一个ID特征分配一个unique embedding vectors,但这也导致存储emb…
基于Embedding召回和DSSM双塔模型
文章目录 基于Embedding召回介绍基于Embedding召回算法分类I2I召回U2I召回 DSSM模型DSSM双塔模型层次 基于Embedding召回介绍
基于embedding的召回是从内容文本信息和用户查询的角度出发,利用预训练的词向量模型或深度学习模型,将文本信息转换成向量进行…
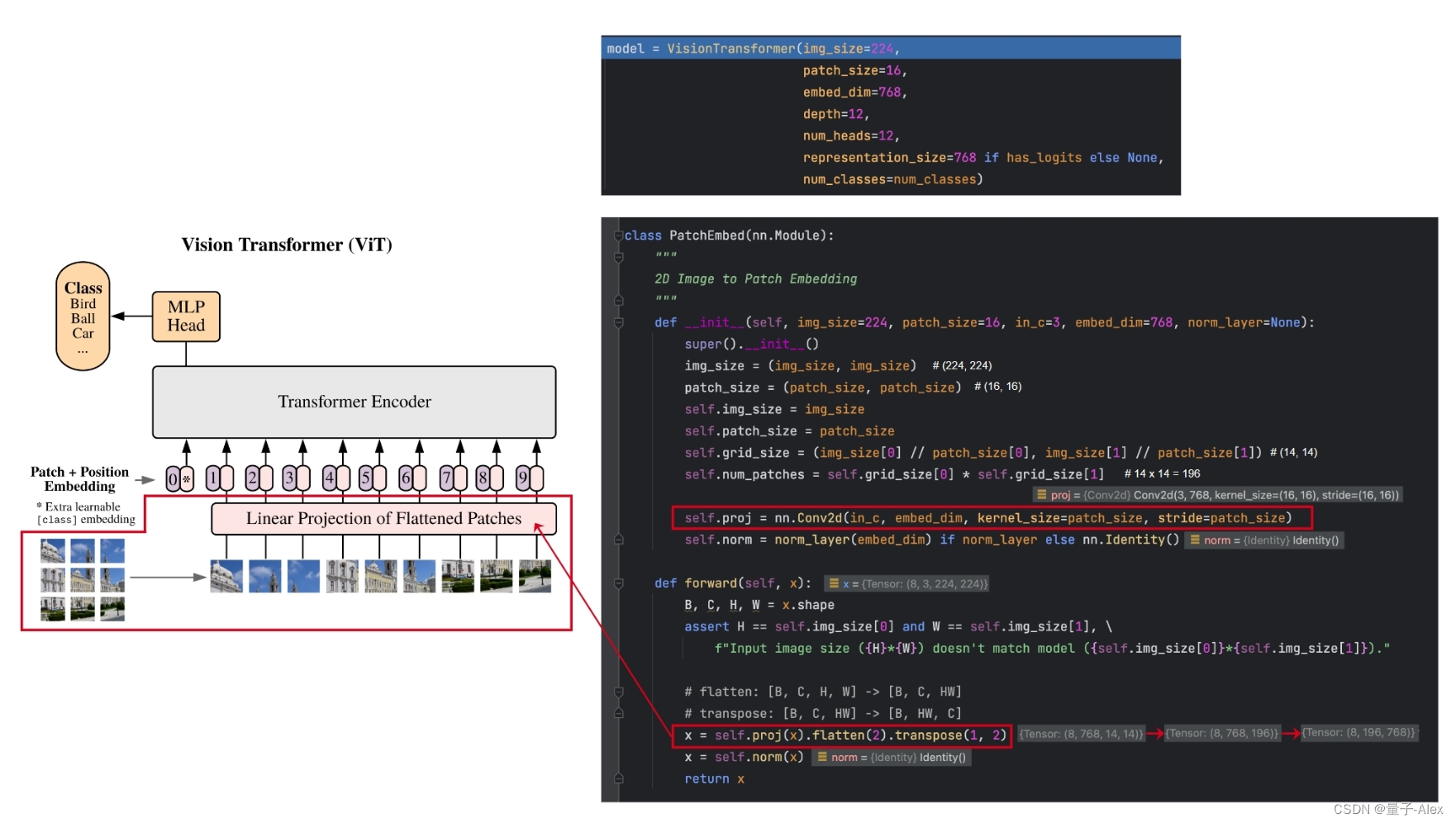
【ViT】Vision Transformer的实现01 patch embedding
对于224*224的图像,将它输入到Transformer里面,就需要将图像展开成一系列的token, 如果逐像素视为token进行注意力的计算,难免计算量太大,因此一个更加合理的想法是将图像划分为一个个的patch 将每个patch进行embeddin…
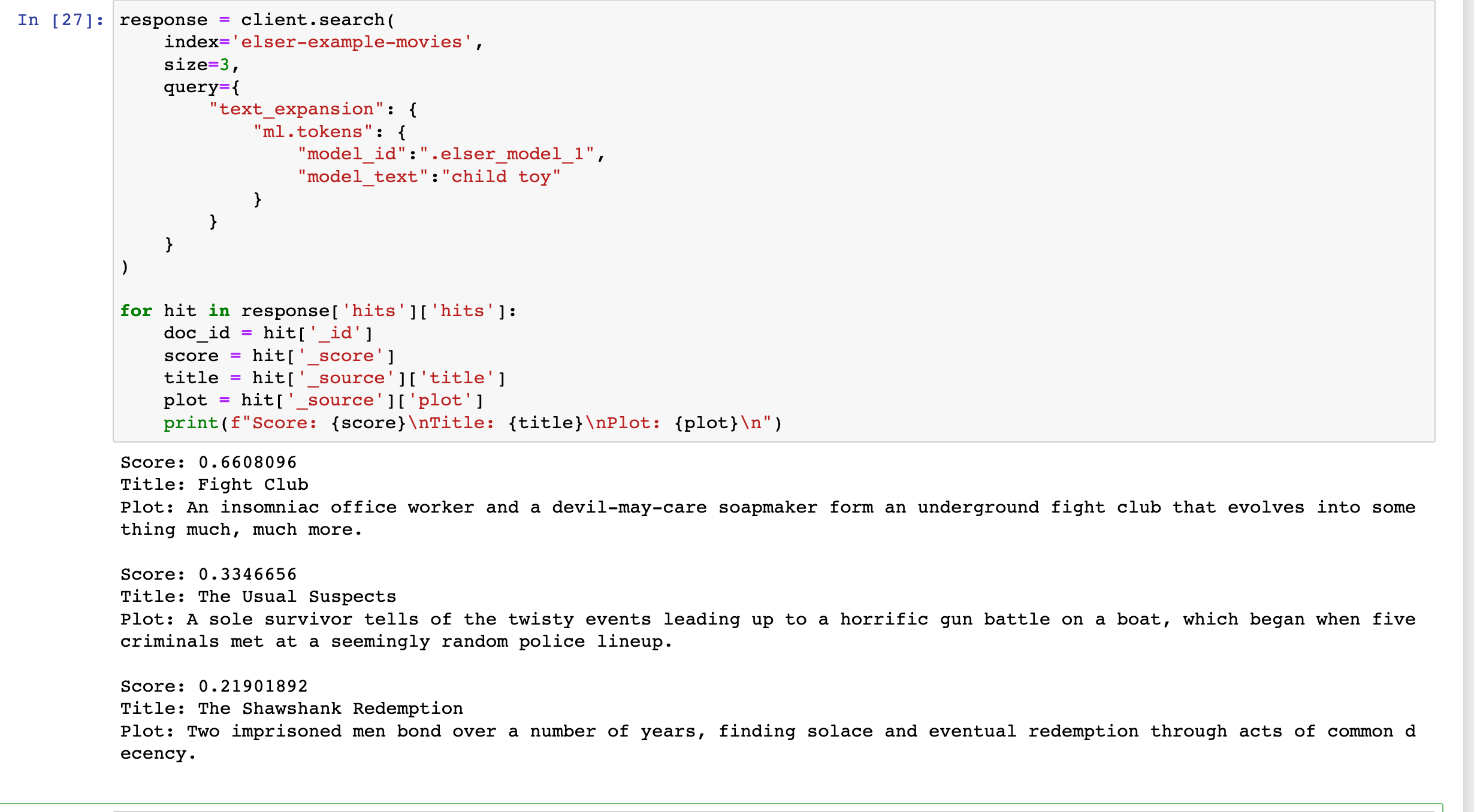
Elasticsearch:使用 ELSER 文本扩展进行语义搜索
在今天的文章里,我来详细地介绍如何使用 ELSER 进行文本扩展驱动的语义搜索。 安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装: 如何在 Linux,MacOS 及 Windows 上…
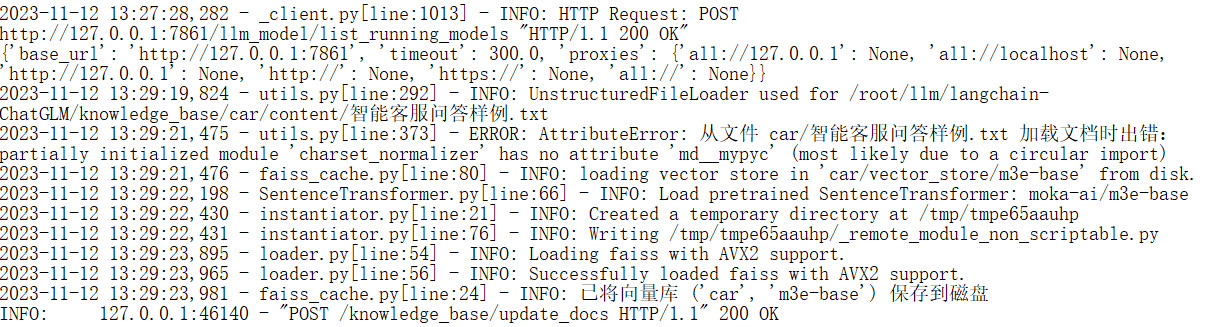
基于LangChain+ChatGLM2-6B+embedding构建行业知识库
目的:最近在探索大模型本地化部署知识库实现行业解决方案,安装过程记录,分享给需要的同学,安装前确定好各组件的版本非常重要,避免重复安装走老路。 经过查阅大量资料,目前可以分为以下两种方案
方案一&am…
基于ChatGPT+词向量/词嵌入实现相似商品推荐
最近一个项目有个业务场景是相似商品推荐,给一个商品描述(比如 WIENER A/B 7IN 5/LB FZN ),系统给出商品库中最相似的TOP 5种商品,这种单纯的推荐系统用词向量就可以实现,不过,这个项目特点是商品库巨大,有…
【人工智能】神奇的Embedding:文本变向量,大语言模型智慧密码解析(10)
什么是嵌入?
OpenAI 的文本嵌入衡量文本字符串的相关性。嵌入通常用于:
Search 搜索(结果按与查询字符串的相关性排序)Clustering 聚类(文本字符串按相似性分组)Recommendations 推荐(推荐具有…
NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding
2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的wor…
insightface提取embedding
最近在复现一篇文章(Mate Portrait)的训练模型,需要自己提取人脸的特征向量,按照作者给的参考,用insightface提取。
1. 安装
安装MXNex:insightface时基于MXNet框架开发的
pip install mxnet-cu101 # 如…
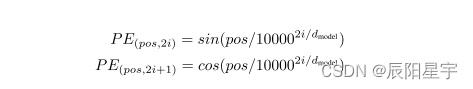
【Transformer从零开始代码实现】(一)输入部件:embedding+positionalEncoding
Transformer总架构图 输入相关组件
输入部分:
源文本嵌入层位置编码器目标文本嵌入层位置编码器
(1)Embedding
首先,需要对输入的内容进行向量化。
1)先导示例
nn.Embedding示例:
# 10代表嵌入的数…
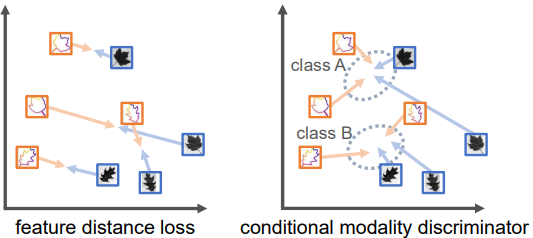
SELF-AUGMENTED MULTI-MODAL FEATURE EMBEDDING
two embeddings f o r g _{org} org and f a u g _{aug} aug are combined using a gating mechanism 作者未提供代码

如何利用大语言模型(LLM)打造定制化的Embedding模型
一、前言
在探索大语言模型(LLM)应用的新架构时,知名投资公司 Andreessen Horowitz 提出了一个观点:向量数据库是预处理流程中系统层面上最关键的部分。它能够高效地存储、比较和检索高达数十亿个嵌入(也就是向量&…

【Pytorch:nn.Embedding】简介以及使用方法:用于生成固定数量的具有指定维度的嵌入向量embedding vector
文章目录 1、nn.Embedding2、使用场景 1、nn.Embedding
首先我们讲解一下关于嵌入向量embedding vector的概念 1)在自然语言处理NLP领域,是将单词、短语或其他文本单位映射到一个固定长度的实数向量空间中。嵌入向量具有较低的维度,通常在几…

CS224W3.1——节点Embedding
传统图机器学习流程是这样的: 从之前的文章中,我们看到了如何将机器学习与特征工程结合起来,对节点、链接和图形进行预测。在本文中,我们将重点介绍一种称为图表示学习的新技术,它可以减轻对特征工程的需求。在图表示学…
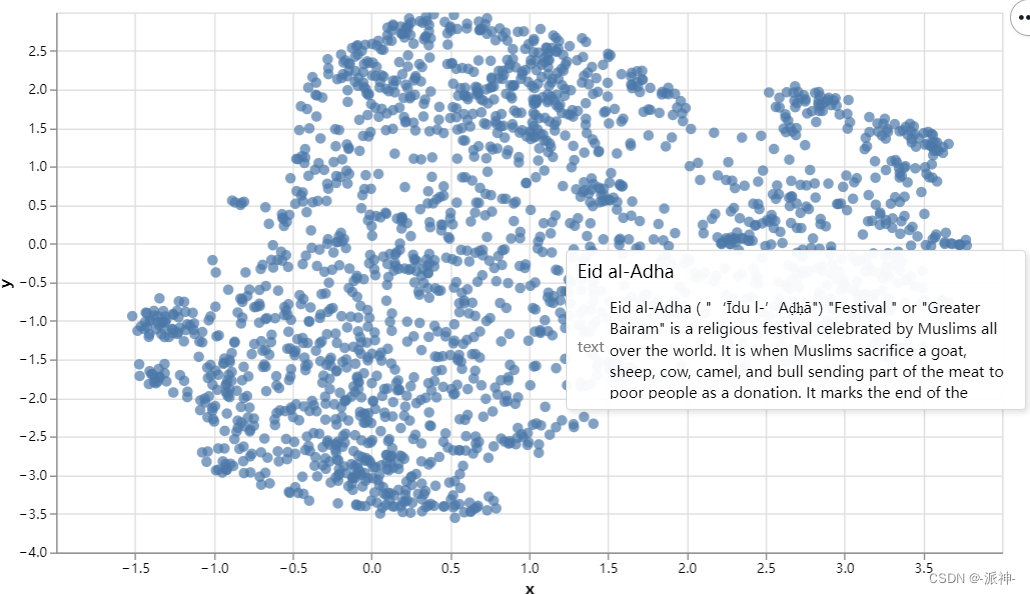
大型语言模型的语义搜索(二):文本嵌入(Text Embeddings)
在我写的上一篇博客:关键词搜索中,我们解释了关键词搜索(Keyword Search)的技术,它通过计算问题和文档中重复词汇的数量,来搜索与问题相关的文档,常用的关键词搜索算法是Okapi BM25,简称BM25,关键词搜索算法的局限性在…
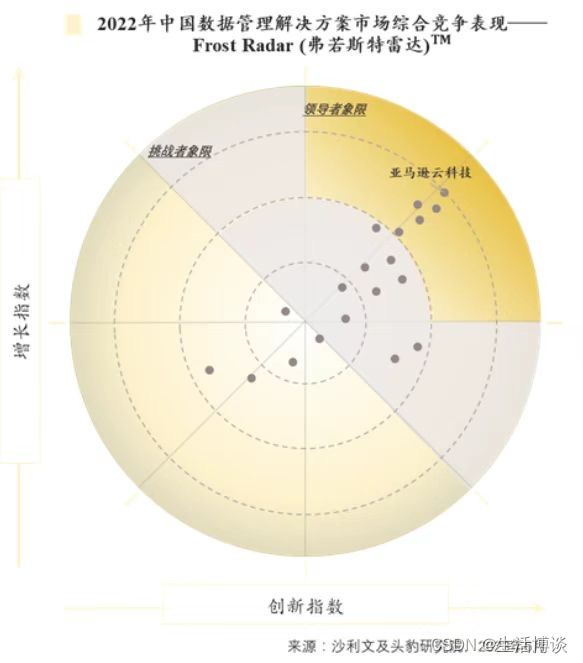
整合来自多个Aurora数据库数据,亚马逊云科技为用户提供数据分析一体化融合解决方案
亚马逊云科技近日在沙利文联合头豹研究院发布的《2023年中国数据管理解决方案市场报告》中再次获评中国数据管理解决方案的领导者位置,并在增长指数和创新指数上获得最高评分。亚马逊云科技凭借其独特的数据服务和数据湖组合、全面的无服务器选项、打破数据传输壁垒…

IMAGEBIND: One Embedding Space To Bind Them All论文笔记
论文https://arxiv.org/pdf/2305.05665.pdf代码https://github.com/facebookresearch/ImageBind
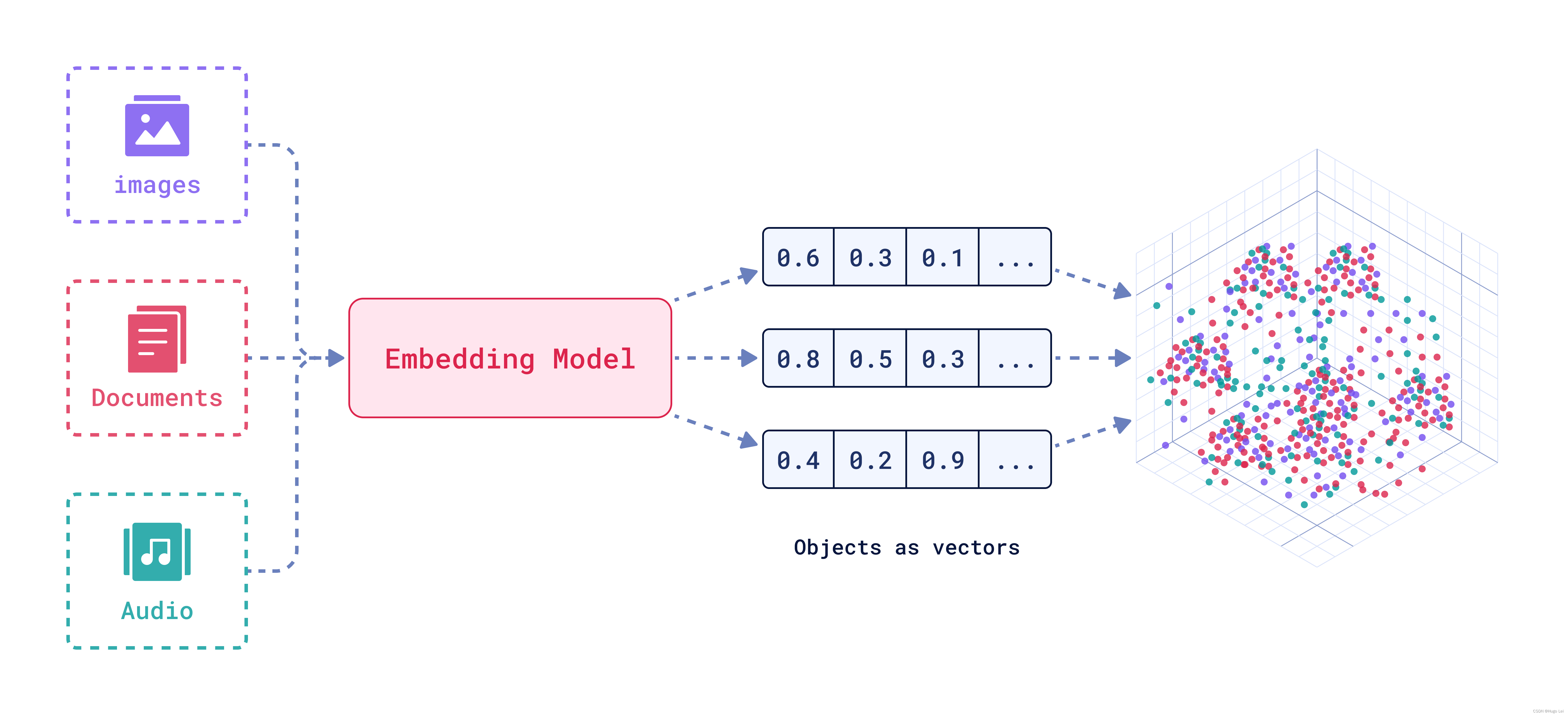
1. Motivation 像CLIP这一类的方法只能实现Text-Image这两个模态的 Embedding 对齐,本文提出的ImageBind能够实现六个模态(images, text, audio, depth, t…

EMNLP 2023 亮点回顾:大模型时代下的 NLP 研究
作为自然语言处理(NLP)领域的顶级盛会,EMNLP 每年都成为全球研究者的关注焦点。2023 年的会议在新加坡举行,聚集了数千名来自世界各地的专家学者,也是自疫情解禁以来,中国学者参会最多的一次。巧的是&#…
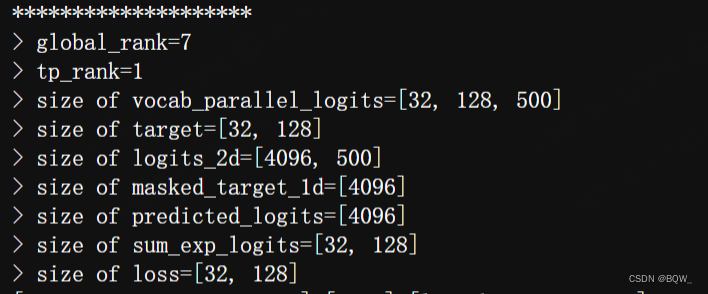
【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试
相关博客 【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试 【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):…
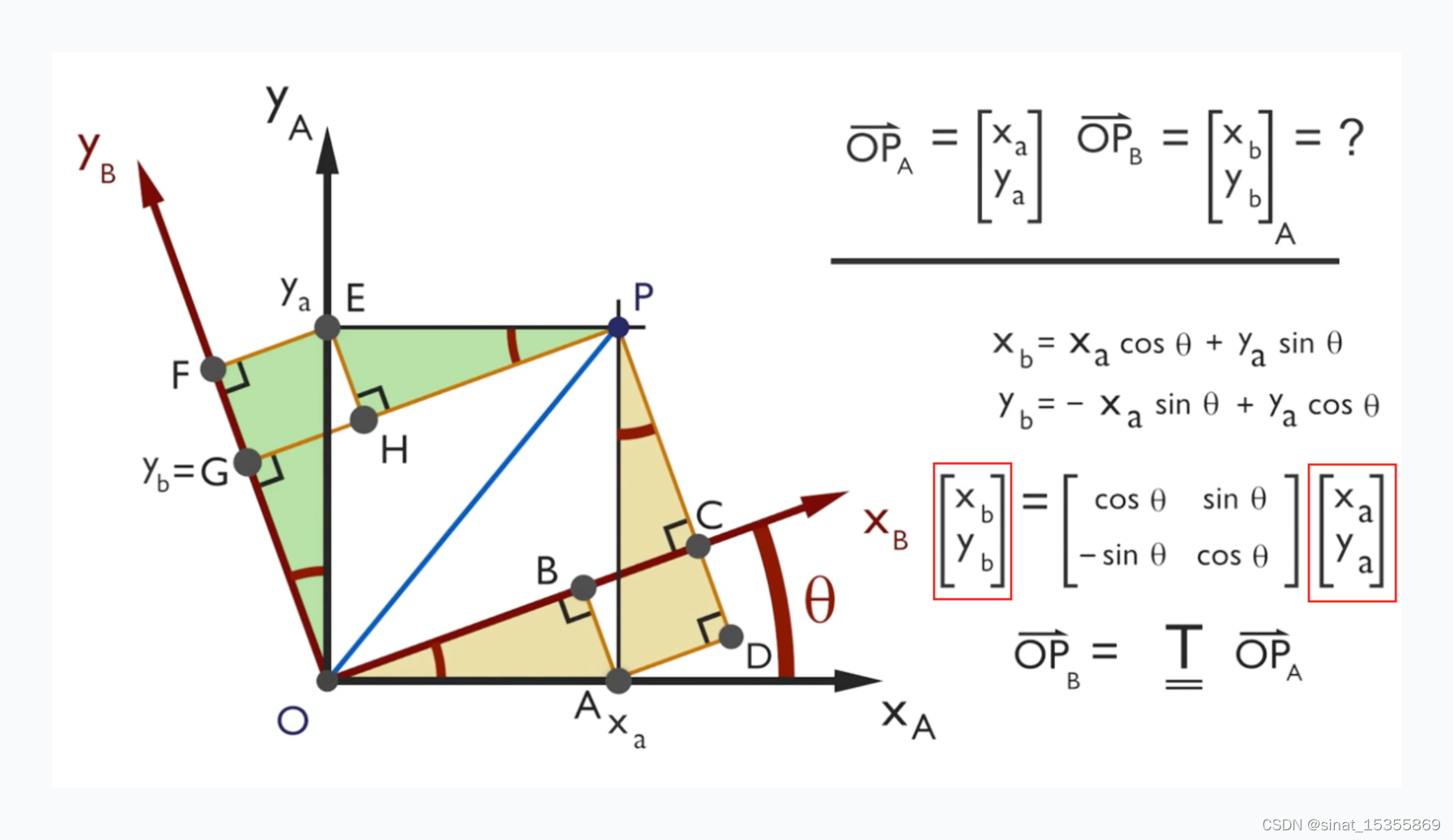
一张图系列 - “position_embedding”
关于位置编码,我感觉应该我需要知道点啥? 0、需要知道什么知识? multi head atten 计算 复数的常识 1、embedding 是什么? position embedding常识、概念,没有会怎样? 交换token位置,没有P…
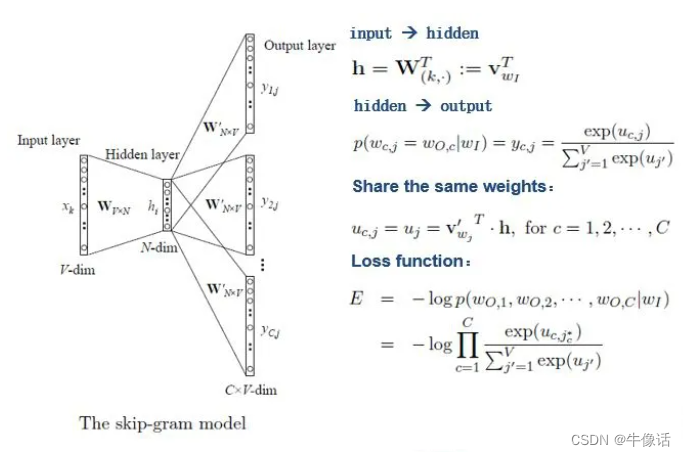
Embedding And Word2vec
Embedding与向量数据库:
Embedding 简单地说就是 N 维数字向量,可以代表任何东西,包括文本、音乐、视频等等。要创建一个Embedding有很多方法,可以使用Word2vec,也可以使用OpenAI 的 Ada。创建好的Embeddingÿ…
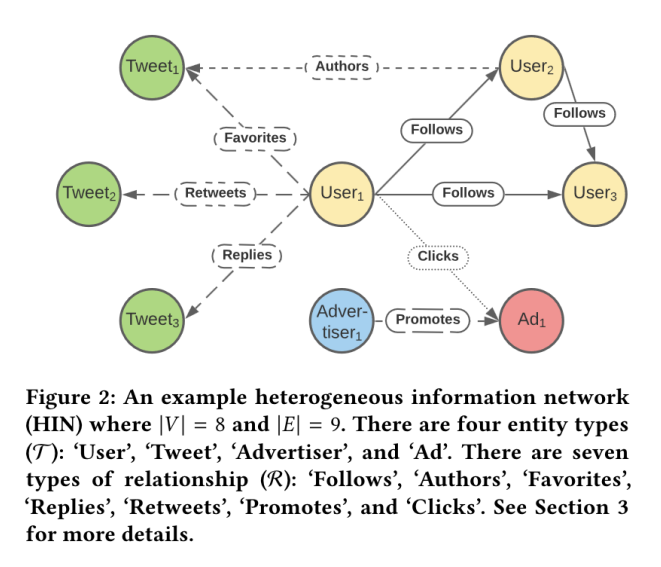
Embedding技术与应用(3):Embeddings技术的实践应用
编者按: IDP开启Embedding系列专栏,力图详细介绍Embedding的发展史、主要技术和应用。 本文是《Embedding技术与应用系列》的第三篇,重点介绍 嵌入技术在生产环境中的应用效果到底如何。 文章作者认为,嵌入技术可以有效地表示用户…
多场景建模:快手参数及Embedding个性化网络PEPNet
Parameter and Embedding Personalized Network (PEPNet)
背景
多场景:双列Tab(Double-Columned Discovery Tab)、精选Tab(the Featured-Video Tab)、沉浸单列Tab(the Single-Columned Slide Tab…
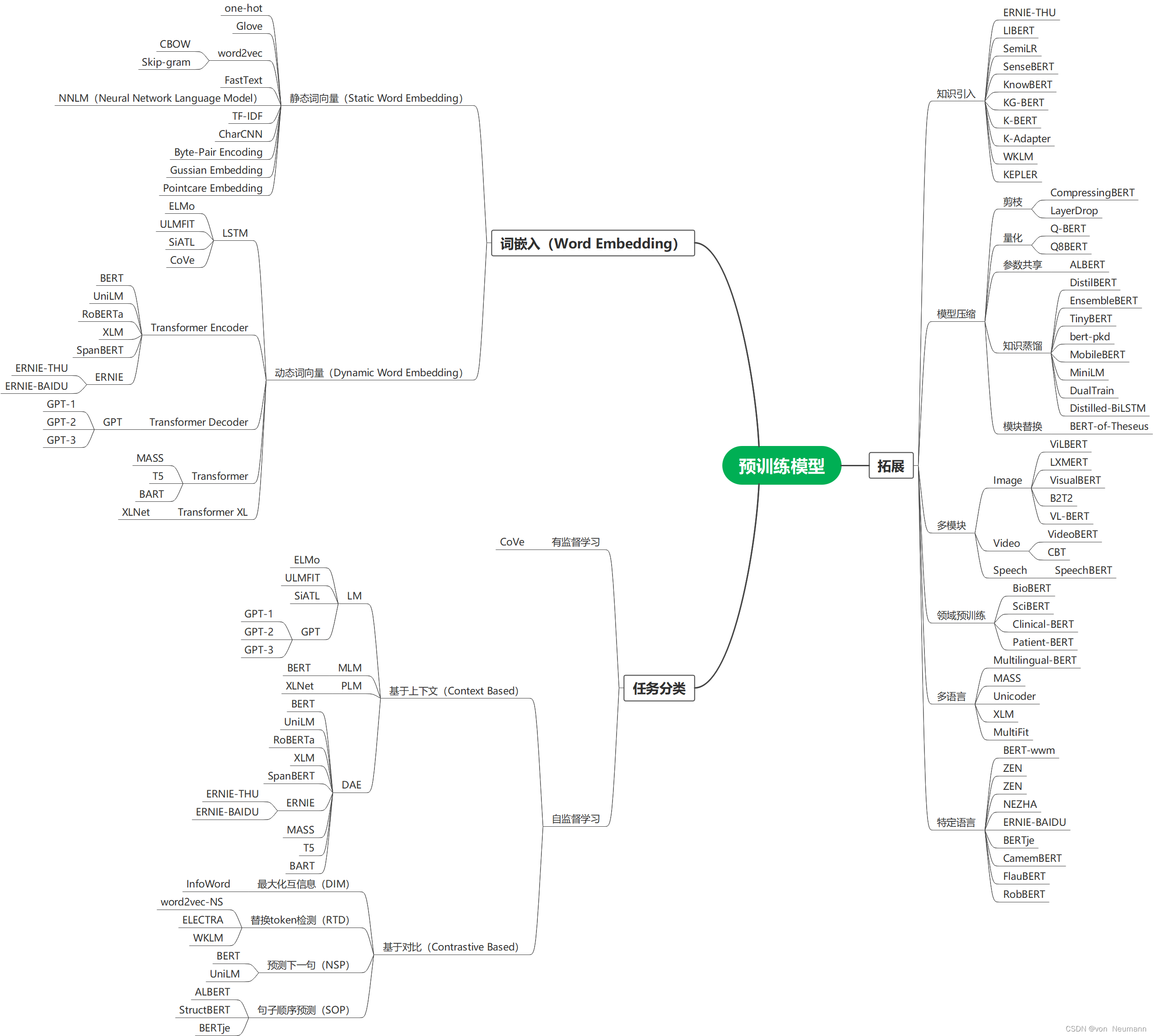
自然语言处理从入门到应用——预训练模型总览:词嵌入的两大范式
分类目录:《自然语言处理从入门到应用》总目录 相关文章: 预训练模型总览:从宏观视角了解预训练模型 预训练模型总览:词嵌入的两大范式 预训练模型总览:两大任务类型 预训练模型总览:预训练模型的拓展 …
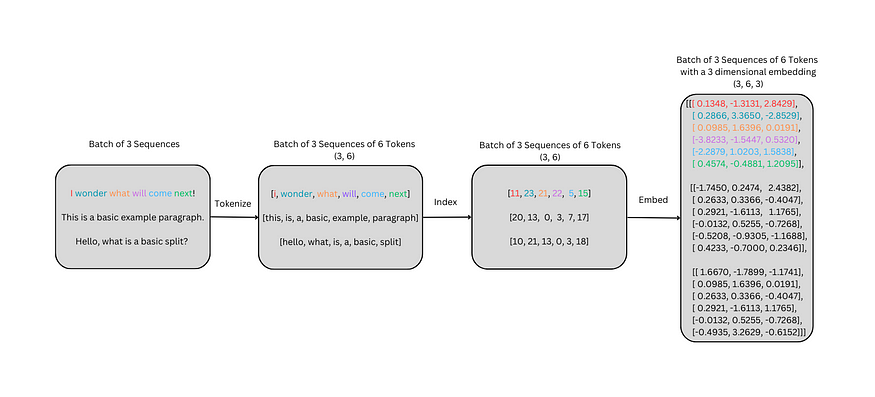
学习transformer模型-Input Embedding 嵌入层的简明介绍
今天介绍transformer模型的Input Embedding 嵌入层。 背景 嵌入层的目标是使模型能够更多地了解单词、标记或其他输入之间的关系。 从头开始嵌入Embeddings from Scratch 嵌入序列需要分词器tokenizer、词汇表和索引,以及词汇表中每个单词的三维嵌入。Embedding a s…

深度学习中什么是embedding
使用One-hot 方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当使用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,如果字典再大一点,…

自然语言处理中关键概念——词嵌入(Word Embedding)
词嵌入(Word Embedding)是一种在自然语言处理中广泛使用的表示方法,它将离散的词汇表中的每个词转换为一个连续向量空间中的稠密向量。这种低维度实数向量能够捕捉词语之间的语义和句法关系。 通过训练神经网络模型(如word2vec、G…
LangChain+LLM实战---Embedding Model
原文地址:Choosing the Right Embedding Model: A Guide for LLM Applications
什么是向量Embedding
在AI聊天机器人的开发领域中,向量Embedding在获取文本信息的本质方面起着关键作用。向量Embedding的核心是指在数学空间中将单词、句子甚至整个文档表…

【NLP学习记录】Embedding和EmbeddingBag
Embedding与EmbeddingBag详解
●🍨 本文为🔗365天深度学习训练营 中的学习记录博客
●🍖 原作者:K同学啊 | 接辅导、项目定制
●🚀 文章来源:K同学的学习圈子1、Embedding详解
Embedding是Pytorch中最基本…
深度学习:到底怎么理解embedding
深度学习:到底怎么理解embedding 注意到embedding这个词,很大可能是在进行时间序列上的处理过程中遇到的,遇到的时间序列模型中,很大部分需要用到embedding过程,同时在看相关的程序代码的时候看到模型的结构设计中设计…
![【PyTorch][chapter 14][李宏毅深度学习][Word Embedding]](https://img-blog.csdnimg.cn/direct/5a0d9329961548059fa6e33b7c22869e.png)
【PyTorch][chapter 14][李宏毅深度学习][Word Embedding]
前言: 这是用于自然语言处理中数据降维的一种方案。
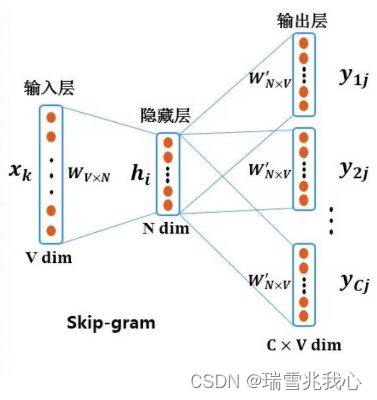
我们希望用一个向量来表示每一个单词. 有不同的方案 目录: one-hot Encoding word-class 词的上下文表示 count-based perdition-based CBOW Skip-Gram word Embedding 词向量相似…

使用 OpenAI 的 text-embedding 构建知识向量库并进行相似搜索
OpenAI的embedding模型的使用 首先第一篇文章中探讨和使用了ChatGPT4的API-Key实现基础的多轮对话和流式输出,完成了对GPT-API的一个初探索,那第二步打算使用OpenAI的embedding模型来构建一个知识向量库,其实知识向量库本质上就是一个包含着一…
【论文阅读随笔】RoPE/旋转编码:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
文章目录 1.目的:通过绝对位置编码的方式实现相对位置编码2.理解RoPE,在我看来有几个需要注意的点:3.本文相关复数概念:3.1.复数乘法的几何意义3.2.复数内积 VS. 复数乘法 4.REF: 1.目的:通过绝对位置编码的…
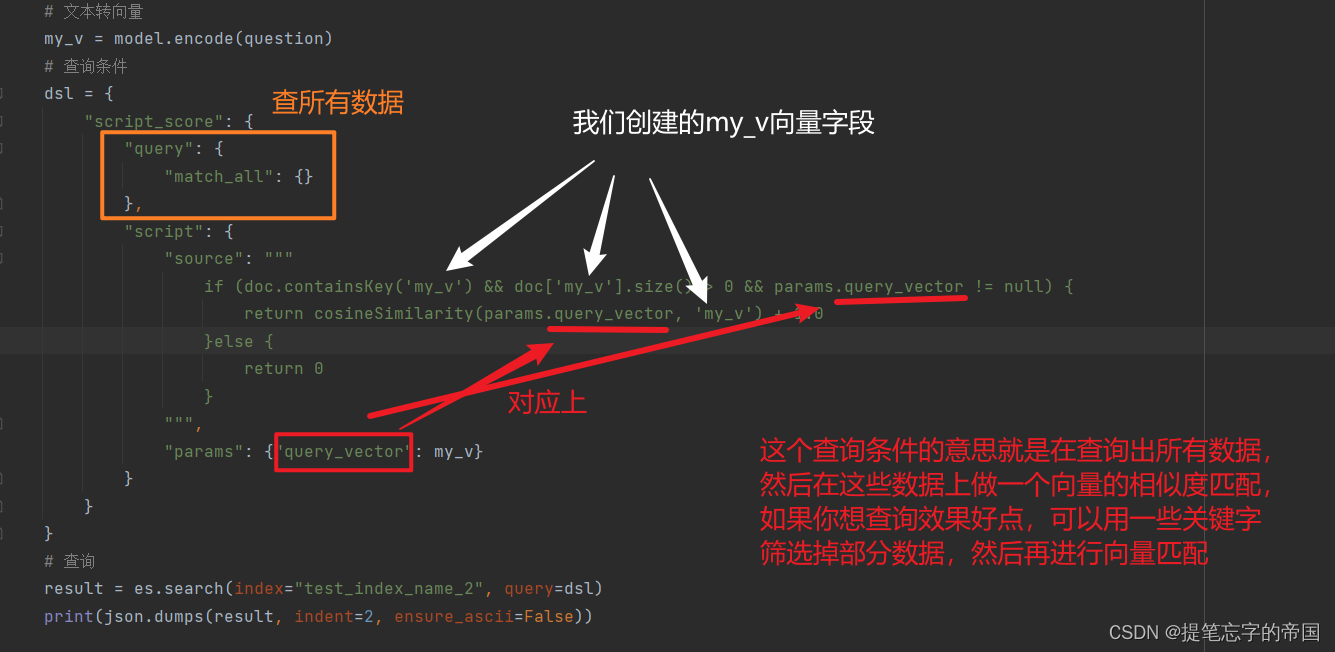
ElasticSearch7.x + kibana7.x使用记录
目录
查询所有索引
查询索引的mapping信息
添加索引的同时添加mapping
在原有基础上新增字段
旧的索引迁移到新的索引(使用场景:数据迁移、索引优化、数据转换) 查询索引下的文档总数
场景1:某一个字段的值是数组࿰…

AI大模型的使用-语义检索,利用Embedding优化你的搜索功能
Embedding 向量适合作为一个中间结果,用于传统的机器学习场景,比如分类、聚类。
Completion 接口,一方面可以直接拿来作为一个聊天机器人,另一方面,你只要善用提示词,就能完成合理的文案撰写、文本摘要、机…
深度学习:pytorch nn.Embedding详解
目录 1 nn.Embedding介绍
1.1 nn.Embedding作用
1.2 nn.Embedding函数描述
1.3 nn.Embedding词向量转化
2 nn.Embedding实战
2.1 embedding如何处理文本
2.2 embedding使用示例
2.3 nn.Embedding的可学习性 1 nn.Embedding介绍
1.1 nn.Embedding作用
nn.Embedding是Py…
关于torch.nn.Embedding的浅显理解
最近在使用词嵌入向量表示我的数据标签,并且在试图理解torch.nn.Embedding函数。 torch.nn.Embedding(num_embeddings, embedding_dim, padding_idxNone, max_normNone, norm_type2.0, scale_grad_by_freqFalse, sparseFalse, _weightNone, _freezeFalse, deviceNon…
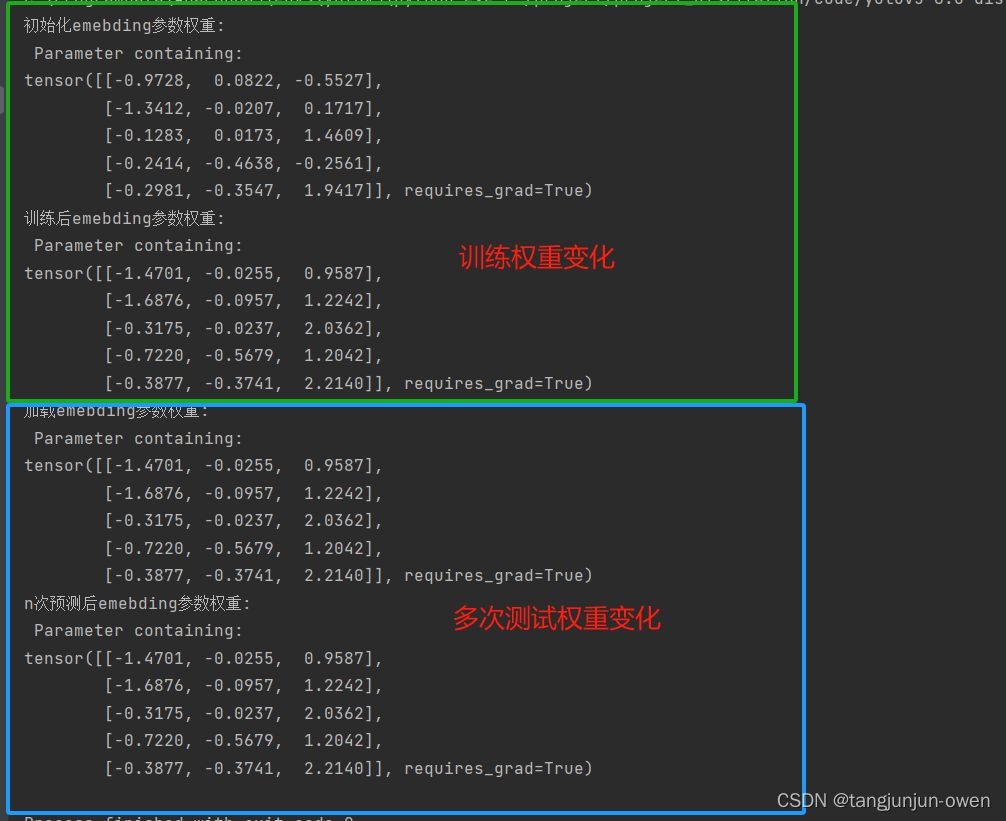
nn.embedding函数详解(pytorch)
提示:文章附有源码!!! 文章目录 前言一、nn.embedding函数解释二、nn.embedding函数使用方法四、模型训练与预测的权重变化探讨 前言
最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函…

30秒搞定一个属于你的问答机器人,快速抓取网站内容
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 文章目录 简介运行效果GitHub地址 简介
爬取一个网站的内容,然后让这个内容变成你自己的私有知识库,并且还可以搭建一个基于私有知识库的问…
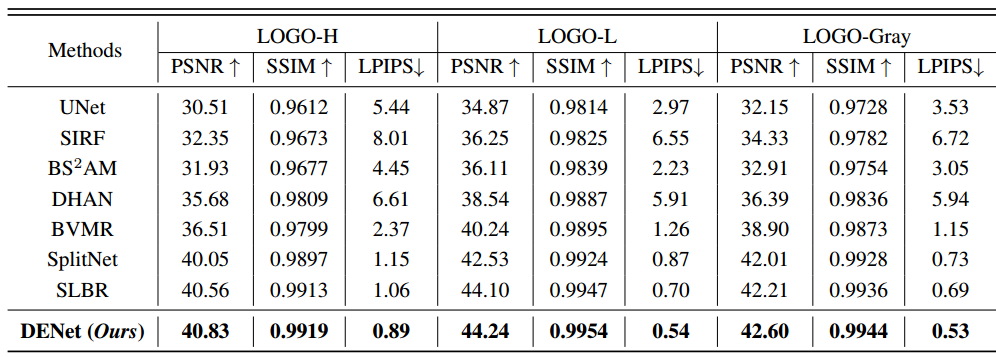
DENet:用于可见水印去除的Disentangled Embedding网络笔记
1 Title DENet: Disentangled Embedding Network for Visible Watermark Removal(Ruizhou Sun、Yukun Su、Qingyao Wu)[AAAI2023 Oral]
2 Conclusion This paper propose a novel contrastive learning mechanism to disentangle the high-level embedd…

![[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING](https://img-blog.csdnimg.cn/direct/3225793bcde54836b6d438d3c796f44b.png)
[RoFormer]论文实现:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
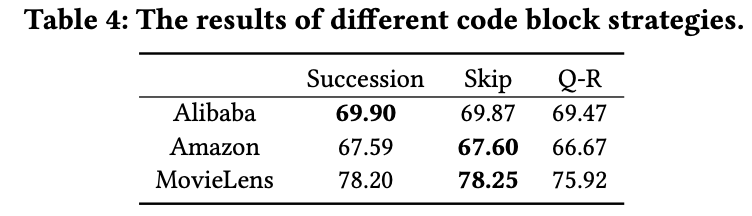
文章目录 一、完整代码二、论文解读2.1 注意力机制2.2 绝对位置编码2.3 相对位置编码2.4 旋转位置编码Long-term decayAdaption for linear attention 2.5 模型效果 三、过程实现四、整体总结 论文:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING …

AI 绘画Stable Diffusion 研究(十五)SD Embedding详解
大家好,我是风雨无阻。
本期内容:
Embedding是什么?Embedding有什么作用?Embedding如何下载安装?如何使用Embedding? 大家还记得 AI 绘画Stable Diffusion 研究(七) 一文读懂 Stab…

Stable Diffusion——基础模型、VAE、LORA、Embedding各个模型的介绍与使用方法
前言
Stable Diffusion(稳定扩散)是一种生成模型,基于扩散过程来生成高质量的图像。它通过一个渐进过程,从一个简单的噪声开始,逐步转变成目标图像,生成高保真度的图像。这个模型的基础版本是基于扩散过程…
LangChain(0.0.340)官方文档九:Retrieval——Text embedding models、Vector stores、Indexing
LangChain官网、LangChain官方文档 、langchain Github、langchain API文档、llm-universe 文章目录 一、Text embedding models1.1 Embeddings类1.2 OpenAI1.3 Sentence Transformers on Hugging Face1.4 CacheBackedEmbeddings1.4.1 简介1.4.2 与Vector Store一起使用1.4.3 内…
![【PyTorch][chapter 15][李宏毅深度学习][Neighbor Embedding-LLE]](https://img-blog.csdnimg.cn/direct/091f57fee7244cd8abac80af960ede62.png)
【PyTorch][chapter 15][李宏毅深度学习][Neighbor Embedding-LLE]
前言: 前面讲的都是线性降维,本篇主要讨论一下非线性降维.
流形学习(mainfold learning)是一类借鉴了拓扑流行概念的降维方法. 如上图,欧式距离上面 A 点跟C点更近,距离B 点较远 但是从图形拓扑结构来看, …

白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…
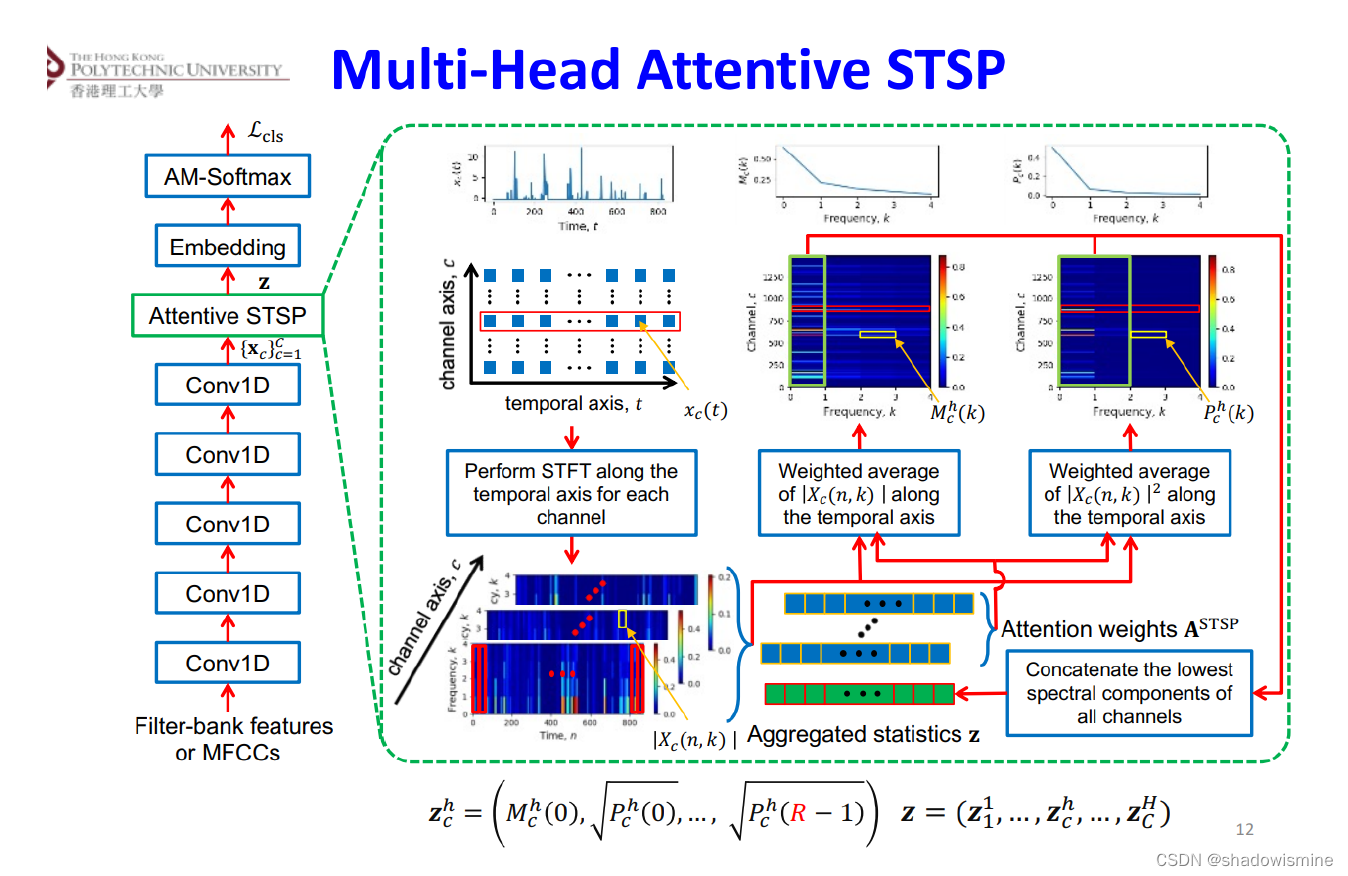
Pooling方法总结(语音识别)
Pooling layer将变长的frame-level features转换为一个定长的向量。 1. Statistics Pooling
链接:http://danielpovey.com/files/2017_interspeech_embeddings.pdf
The default pooling method for x-vector is statistics pooling.
The statistics pooling laye…
【大模型知识库】(5):本地环境运行dity+fastchat的BGE模型,可以使用embedding接口对知识库进行向量化,连调成功。
1,视频演示地址
2,关于 dify 项目
https://github.com/langgenius/dify/blob/main/README_CN.md
Dify 是一个 LLM 应用开发平台,已经有超过 10 万个应用基于 Dify.AI 构建。它融合了 Backend as Service 和 LLMOps 的理念,涵盖…
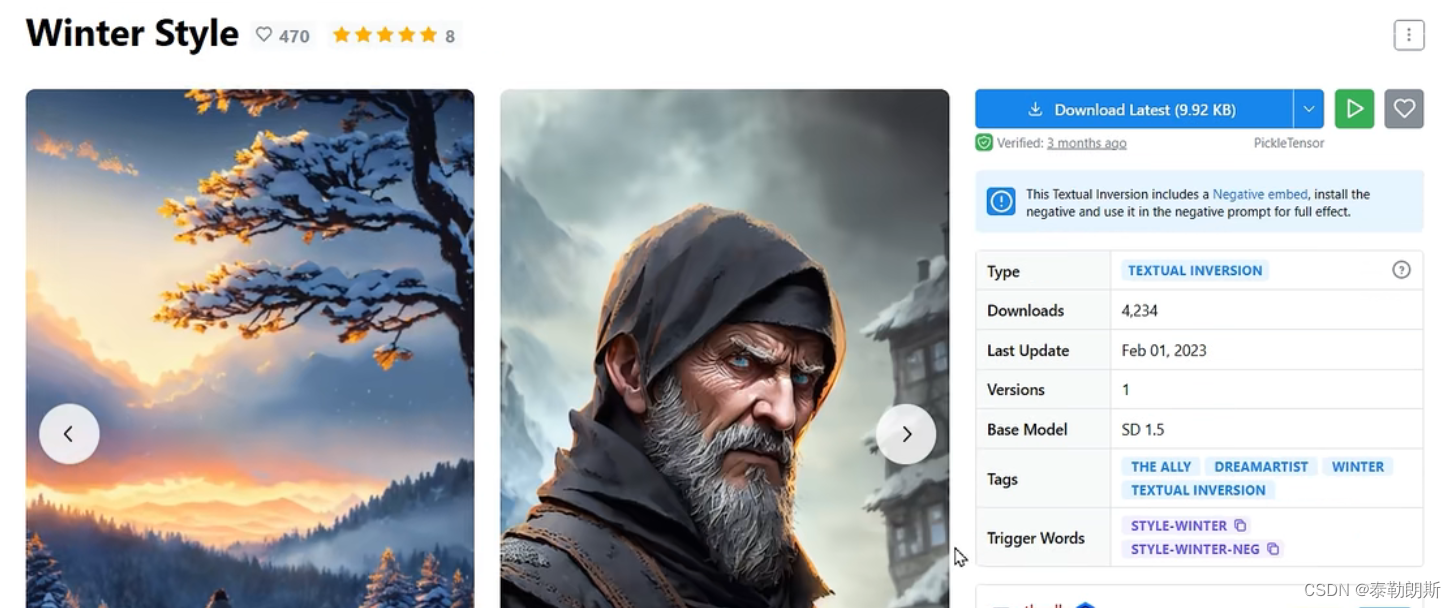
stable diffusion实践操作-embedding(TEXTUAL INVERSION)
本文专门开一节写图生图相关的内容,在看之前,可以同步关注: stable diffusion实践操作
中文名为文本反转,可以理解为提示词的集合,提示词打包,可以省略大量的提示词。后缀safetensors,大小几十…
nn.Embedding()个人记录
维度
import torch.nn as nnembedding nn.Embedding(num_embeddings 10, embedding_dim 256)
nn.Embedding()随机产生一个权重矩阵weight,维度为(num_embeddings, embedding_dim)
输入维度(batch_size, Seq_len)…
基于llama-index对embedding模型进行微调
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回答…
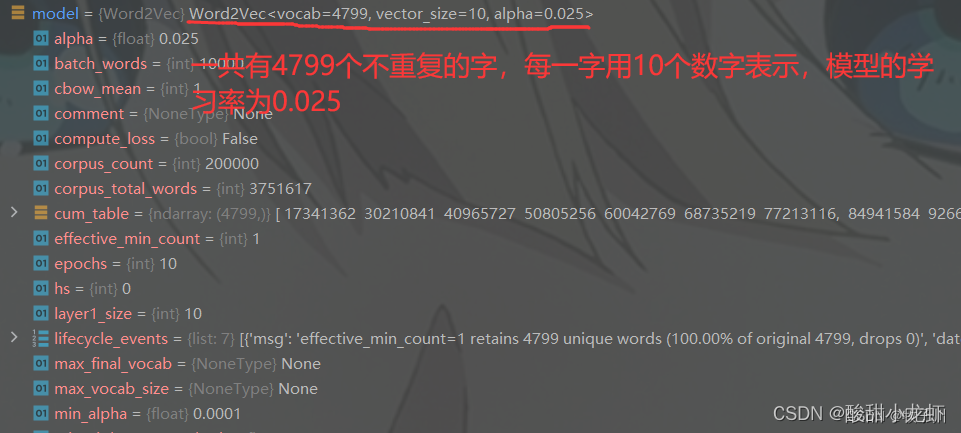
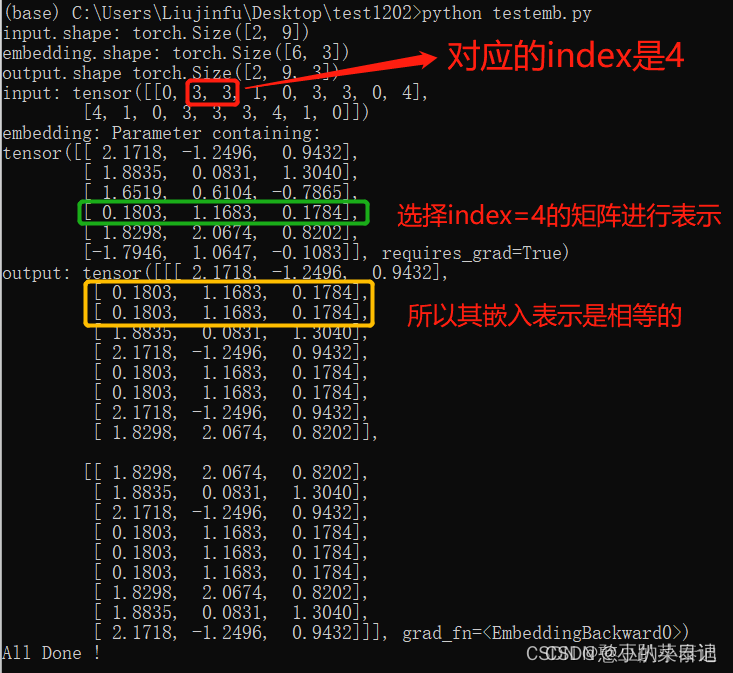
pytorch nn.Embedding 读取gensim训练好的词/字向量(有例子)
最近在跑深度学习模型,发现Embedding随机性太强导致模型结果有出入,因此考虑固定初始随机向量,既提前训练好词/字向量,不多说上代码!!
1、利用gensim训练字向量(词向量自行修改)
#…
人脸识别领域 landmark_2d_106,landmark_23d_64,embedding 特征
1. 人脸识别领域 landmark_2d_106 在人脸识别领域,landmark_2d_106是指对人脸的106个关键点进行的二维标定。这些关键点通常包括眼睛、眉毛、鼻子、嘴唇等部位的位置。通过准确地识别和定位这些关键点,可以帮助系统更准确地识别人脸并进行人脸属性分析、…

Embedding模型在大语言模型中的重要性
引言
随着大型语言模型的发展,以ChatGPT为首,涌现了诸如ChatPDF、BingGPT、NotionAI等多种多样的应用。公众大量地将目光聚焦于生成模型的进展之快,却少有关注支撑许多大型语言模型应用落地的必不可少的Embedding模型。本文将主要介绍为什么…

【腾讯云云上实验室-向量数据库】探索腾讯云向量数据库:全方位管理与高效利用多维向量数据的引领者
目录 前言1 腾讯云向量数据库介绍2 向量数据库信息及设置2.1 向量数据库实例信息2.2 实例监控2.3 密钥管理2.4 安全组2.5 Embedding2.6 可视化界面 3 可视化界面4 Embedding4.1 embedding_coll精确查询4.2 unenabled_embedding_coll精确查询 5 数据库5.1 创建数据库5.2 插入数据…
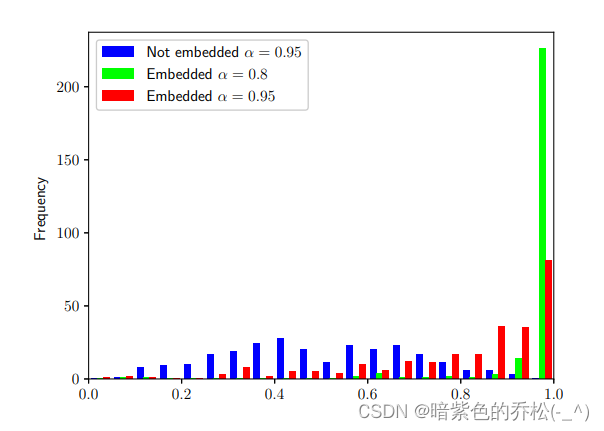
Embedding Watermarks into Deep Neural Networks
将水印嵌入深度神经网络
ABSTRACT
最近在深度神经网络领域取得了显著的进展。分享深度神经网络的训练模型对于这些系统的快速研究课并发进展至关重要。与此同时,保护共享训练模型的权利也变得十分必要。为此我们提议使用数字水印技术来保护知识产权,并…
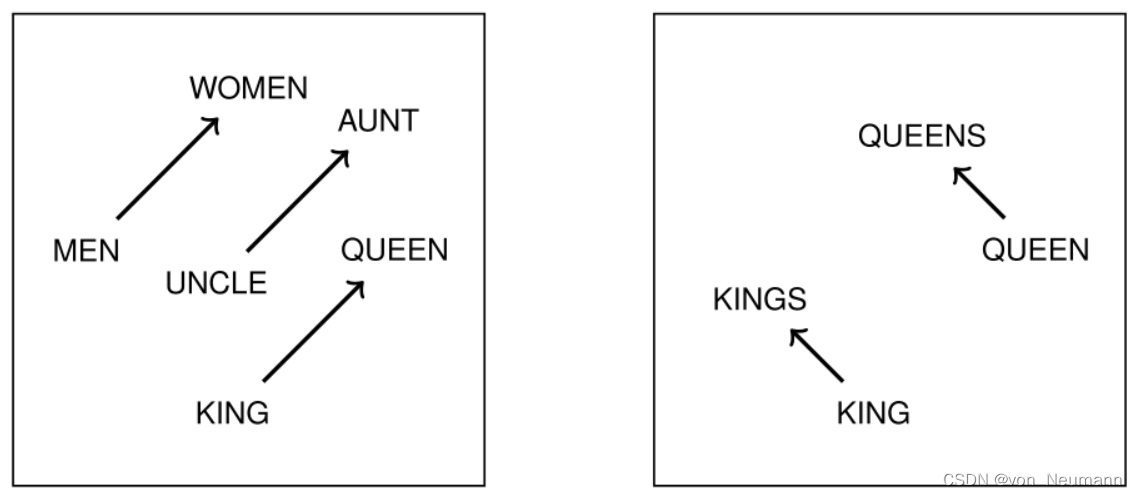
自然语言处理从入门到应用——词向量的评价方法
分类目录:《自然语言处理从入门到应用》总目录 对于不同的学习方法得到的词向量,通常可以根据其对词义相关性或者类比推理性的表达能力进行评价,这种方式属于内部任务评价方法(Intrinsic Evaluation)。在实际任务中&am…
「X」Embedding in NLP|Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色? 虽然没有人可以给出完整的答案,但…
深度学习嵌入头embedding head解释
在目标跟踪或目标检测的深度学习模型中,"嵌入头"(Embedding Head)通常指的是网络架构中负责生成目标的特征表示的部分。具体来说,嵌入头负责将输入图像或图像区域转换为一个高维度的向量(即嵌入向量或特征向…

Keras—embedding嵌入层的使用
最近在工作中进行了NLP的内容,使用的还是Keras中embedding的词嵌入来做的。
Keras中embedding层做一下介绍。
中文文档地址:https://keras.io/zh/layers/embeddings/
参数如下: 其中参数重点有input_dim,output_dim,非必选参数input_lengt…

自然语言处理从小白到大白系列(1)Word Embedding之主题模型
一直想开启一个专题来整理一下NLP的相关内容,总算克服懒癌着手开始干了。如果同学有缘看到这篇,恭喜你,这是本系列(自然语言处理从小白到大白系列)的第一篇,后续会不断更新,欢迎关注!…

SimCSE论文阅读
正负样本对构建原理正样本pair:one sentence two different embeddings as “positive pairs”. (通过dropout 作为噪声)负样本pair:Then we take other sentences in the same mini-batch as “negatives”任务: the model predicts the pos…

Tensorflow - 拿捏 tf.nn.embedding_lookup tf.nn.embedding_lookup_sparse
一.引言
前面提到 Wide & Deep 中涉及到类别特征的 embedding,文中的 embedding 是由 Embedding 层得到,实际应用场景中,也可以从预训练的模型中加载已知 id 的 embedding,例如可以从矩阵分解获取 user-item 的向量ÿ…

Embedding理解、Keras实现Embedding
创建于:20210714 修改于:20210714 文章目录1 Embedding介绍1.1 embedding 有3 个主要目的1.2 图形化解释2 包模块、方法介绍3 Keras实现Embedding4 参考链接1 Embedding介绍
Embedding 是一个将离散变量转为连续向量表示的一个方式。在神经网络中&#…
Embedding 嵌入知识入门
原文首发于博客文章Embedding 嵌入知识入门 文本嵌入是什么
向量是一个有方向和长度的量,可以用数学中的坐标来表示。例如,可以用二维坐标系中的向量表示一个平面上的点,也可以用三维坐标系中的向量表示一个空间中的点。在机器学习中&#x…

EBR开山之作:Embedding-based Retrieval in Facebook Search
目录 简介1 模型2 特征3 索引4 全链路优化 简介
个人的随笔,读者需要基本了解IR领域的基本知识和概念,本文主要记录了我觉得该工作一些重要的点。和大家共勉。
1 模型 标准的双塔结构
1.1 损失函数
搜索相关性以pair-wise的形式进行建模,…
Pytorch中的nn.Embedding()
模块的输入是一个索引列表,输出是相应的词嵌入。
Embedding.weight(Tensor)–形状模块(num_embeddings,Embedding_dim)的可学习权重,初始化自(0,1)。 也就是…
bert 适合 embedding 的模型
目录
背景
embedding
求最相似的 topk
结果查看 背景
想要求两个文本的相似度,就单纯相似度,不要语义相似度,直接使用 bert 先 embedding 然后找出相似的文本,效果都不太好,试过 bert-base-chinese,be…
pytorch中的可学习查找表实现之nn.Embedding
假设我们需要一个查找表(Lookup Table),我们可以根据索引数字快速定位查找表中某个具体位置并读取出来。最简单的方法,可以通过一个二维数组或者二维list来实现。但如果我希望查找表的值可以通过梯度反向传播来修改,那…

文献笔记:LINE: Large-scale Information Network Embedding
paper 看完√
code复现ing https://arxiv.org/pdf/1503.03578v1.pdf
本文研究了将非常大的信息网络嵌入到低维向量空间的问题,这在可视化、节点分类和链路预测等许多任务中都很有用。大多数现有的图形嵌入方法无法扩展到通常包含数百万个节点的现实世界信息网络。…
第N2周:Embeddingbag与Embedding详解
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客**
>- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)** 词嵌入是一种用于自然语…

【CNN】ConvMixer探究ViT的Patch Embedding: Patches Are All You Need?
Patches Are All You Need?
探究Patch Embedding在ViT上的作用,CNN是否可用该操作提升性能?
论文链接:https://openreview.net/pdf?idTVHS5Y4dNvM 代码链接:https://github.com/tmp-iclr/convmixer
1、摘要 ViT的性能是由于T…

Embedding:跨越离散与连续边界——离散数据的连续向量表示及其在深度学习与自然语言处理中的关键角色
Embedding嵌入技术是一种在深度学习、自然语言处理(NLP)、计算机视觉等领域广泛应用的技术,它主要用于将高维、复杂且离散的原始数据(如文本中的词汇、图像中的像素等)映射到一个低维、连续且稠密的向量空间中。这些低…
八、词嵌入语言模型(Word Embedding)
词嵌入(Word Embedding, WE),任务是把不可计算、非结构化的词转换为可以计算、结构化的向量,从而便于进行数学处理。 一个更官方一点的定义是:词嵌入是是指把一个维数为所有词的数量的高维空间(one-hot形式…

如何训练Embedding Model
BGE的技术亮点:
高效预训练和大规模文本微调;在两个大规模语料集上采用了RetroMAE预训练算法,进一步增强了模型的语义表征能力;通过负采样和难负样例挖掘,增强了语义向量的判别力;借鉴Instruction Tuning的…
大模型基础03:Embedding 实战本地知识问答
大模型基础:Embedding 实战本地知识问答
Embedding 概述 知识在计算机内的表示是人工智能的核心问题。从数据库、互联网到大模型时代,知识的储存方式也发生了变化。在数据库中,知识以结构化的数据形式储存在数据库中,需要机器语言(如SQL)才能调用这些信息。互联网时代,…

Word2vec和embedding 非底层算法原理讲解
网上关于二者的信息真的是多如牛毛,参差不齐。 本文不对算法细节进行讲解推导,不从零开始讲二者含义,主要记录些学习中出现的问题。 建议先看完基础知识再浏览,欢迎大家留言指出错误或留下你的疑问。 先贴几个不错的链接
word2ve…
【LLM】大语言模型的前世今生
An Overview of LLMs
LLMs’ status quo
NLP Four Paradigm A timeline of existing large language models 看好OpenAI、Meta 和 LLaMA。
Typical Architectures Casual Decoder eg. GPT3、LLaMA… 在前两篇文章大家也了解到GPT的结构了,在训练模型去预测下一个…
『NLP学习笔记』图解 BERT、ELMo和GPT(NLP如何破解迁移学习)
图解 BERT、ELMo和GPT(NLP如何破解迁移学习) 文章目录 一. 前言二. 示例-句子分类三. 模型架构3.1. 模型输入3.2. 模型输出四. BERT VS卷积神经网络五. 词嵌入新时代5.1. 简要回顾词嵌入Word Embedding5.2. ELMo: 上下文语境很重要5.3. ELMo的秘密是什么?5.4. ULM-FiT:将迁移…

6 时间序列(不同位置的装置如何建模): GRU+Embedding
很多算法比赛经常会遇到不同的物体产生同含义的时间序列信息,比如不同位置的时间序列信息,风力发电、充电桩用电。经常会遇到该如此场景,对所有数据做统一处理喂给模型,模型很难学到区分信息,因此设计如果对不同位置的…

CS224W5.3——信念传播
此文中,我们介绍信念传播,这是一种回答图中概率查询的动态规划方法。通过迭代传递消息给邻居节点,如果达成共识,则计算最终的信念值。然后,我们通过示例和泛化树结构展示消息传递。最后讨论了循环信念传播算法及其优缺…

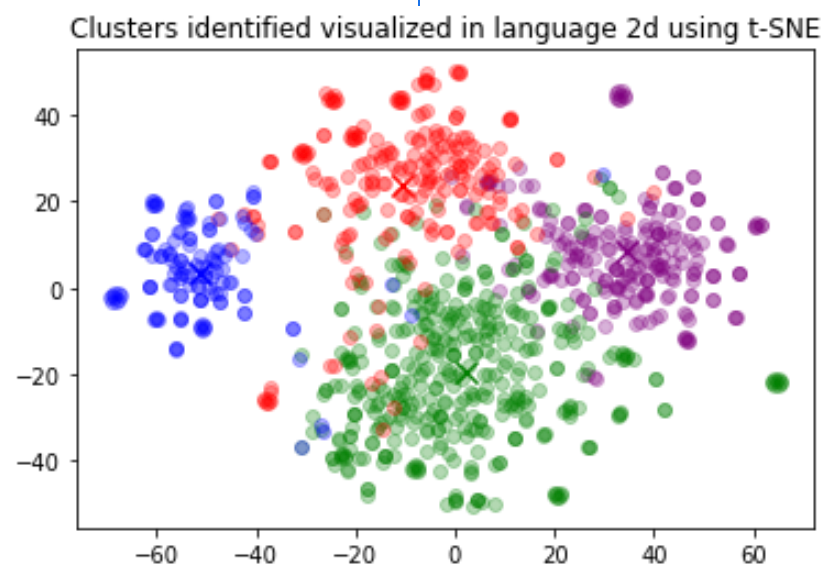
无监督学习 - t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)
什么是机器学习
t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维技术,用于将高维数据映射到低维空间,以便更好地可视化数据的结构。t-SNE主要用于聚类分析和可视化高维数据的相似…
Rotary Position Embedding (RoPE) 旋转位置编码
互联网寻回犬一枚~
这个概念最先由苏神提出,发表在论文《ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING》
简单来说,RoPE用旋转矩阵对绝对位置进行编码,同时将明确的相对位置依赖性纳入到self-att…

OpenAI ChatGPT-4开发笔记2024-06:最简Embedding
Embedding
embedding直译是:嵌入。和实际意思有些差距。其实就是把文本转换为向量表示的过程。用“向量化”更直接,但这又和tensor有点儿混。它是变成向量的一个过程。
embedding 的应用领域:
文本分类: 将文本嵌入转换为向量后…
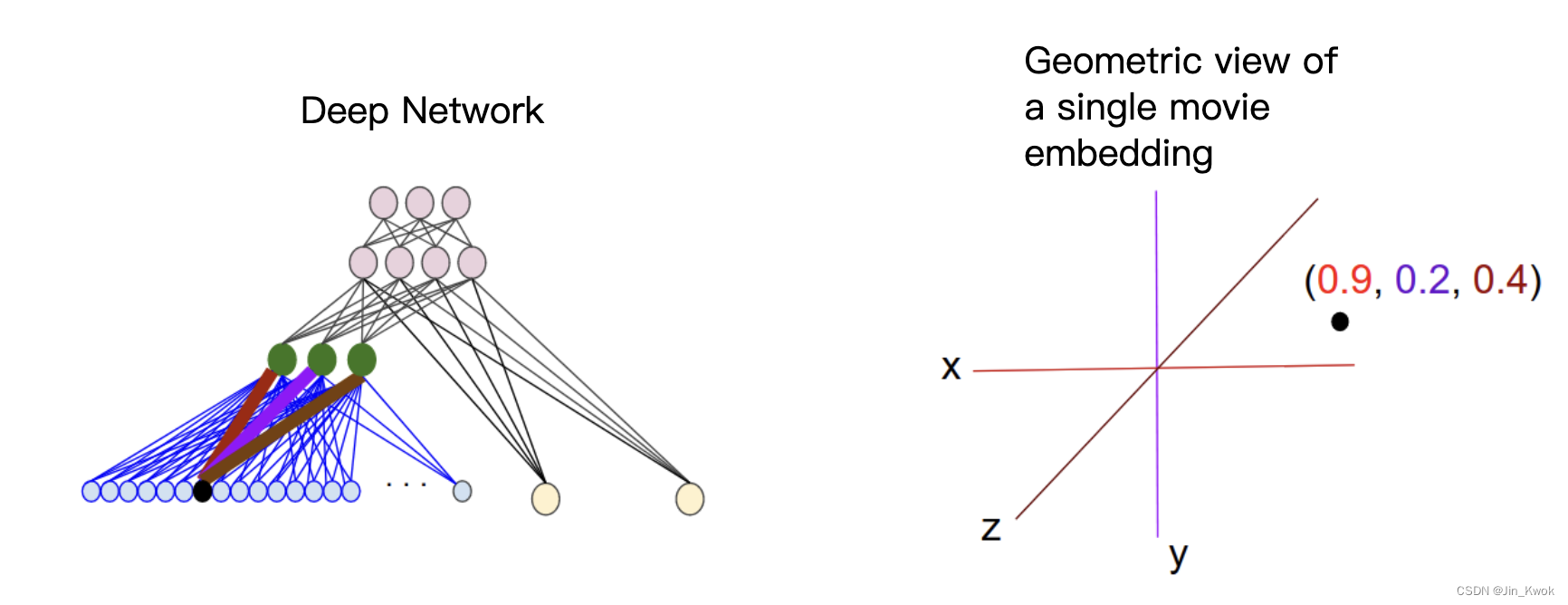
机器学习20:嵌入-Embeddings
嵌入(Embeddings)是一个相对低维的空间,我们可以将高维向量转换到其中。嵌入使得对大型输入(例如表示单词的稀疏向量)进行机器学习变得更加容易。理想情况下,嵌入通过将语义相似的输入紧密地放置在嵌入空间…
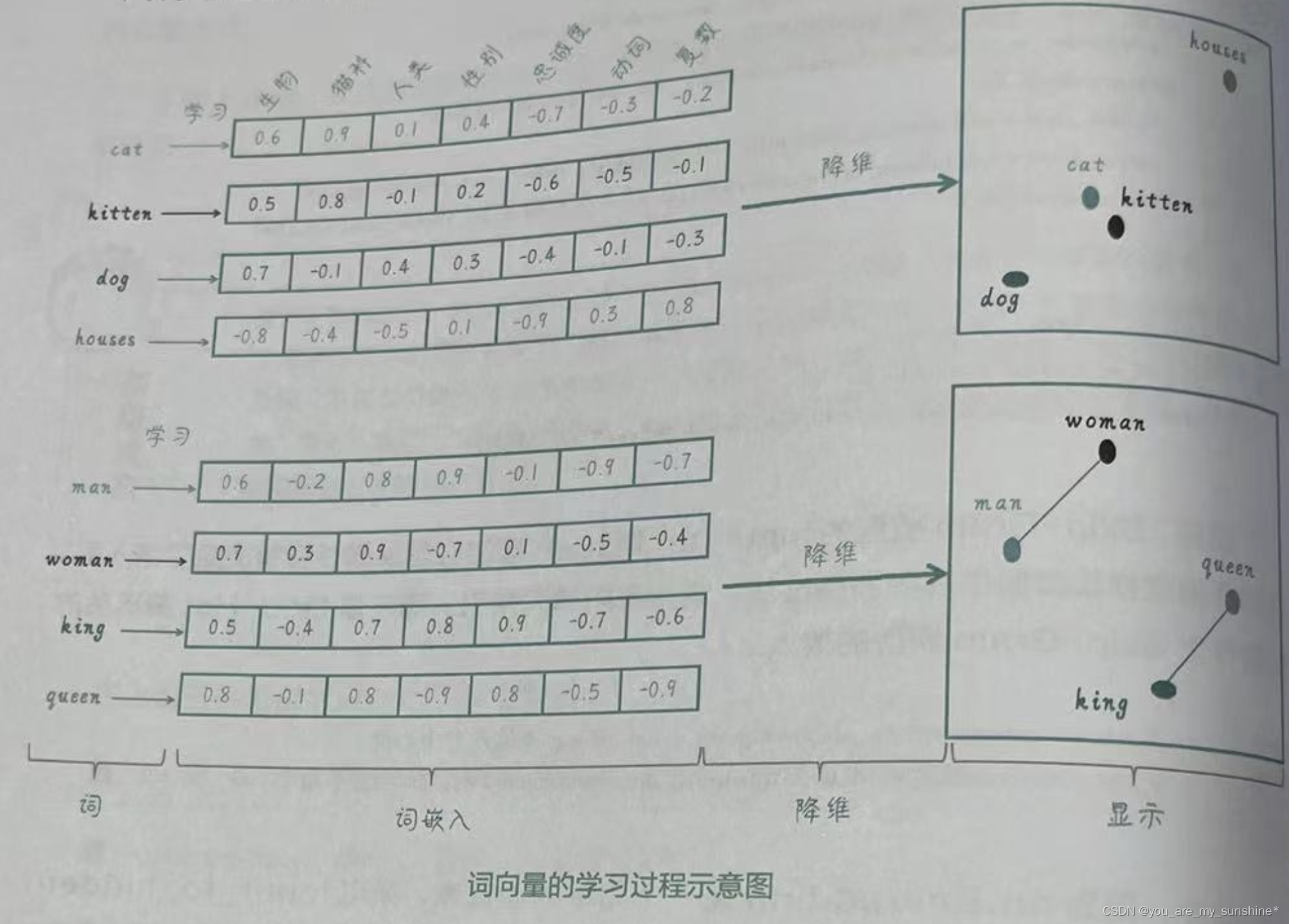
NLP_词的向量表示Word2Vec 和 Embedding
文章目录 词向量Word2Vec:CBOW模型和Skip-Gram模型通过nn.Embedding来实现词嵌入Word2Vec小结 词向量
下面这张图就形象地呈现了词向量的内涵:把词转化为向量,从而捕捉词与词之间的语义和句法关系,使得具有相似含义或相关性的词语在向量空间…

论文阅读:JINA EMBEDDINGS: A Novel Set of High-Performance Sentence Embedding Models
Abstract
JINA EMBEDINGS构成了一组高性能的句子嵌入模型,擅长将文本输入转换为数字表示,捕捉文本的语义。这些模型在密集检索和语义文本相似性等应用中表现出色。文章详细介绍了JINA EMBEDINGS的开发,从创建高质量的成对(pairwi…

C-Pack: Packaged Resources To Advance General Chinese Embedding
简介 论文提出了一个C-pack资源集合,其中包括三个主要的部分:
C-MTEB一个中文综合基准集合,包括6个任务和35个数据集合。C-MTP一个中文embedding数据集合,包括unlabeled和labeled两种数据。C-TEM一个embedding模型家族࿰…
【nlp】1.2文本张量表示方法(词向量word2seq和词嵌入Word Embedding)
文本张量的表示方法 1 one-hot词向量表示1.1 实操演示1.2 one-hot编码使用1.3 one-hot编码的优劣势2 word2vec模型2.1 模型介绍2.2 word2dev的训练和使用2.2.1 数据集的下载与预处理2.2.2 词向量的训练2.2.3 查询单词对应的词向量2.2.4 模型效果检验2.2.5 网络超参数设定3 词嵌…
使用预训练的嵌入向量
先保存模型训练的嵌入向量
a_embedding_weights model.a_embeddings.weight.data.cpu().numpy()
b_embedding_weights model.b_embeddings.weight.data.cpu().numpy()
np.savez(model_weights.npz, a_embeddinga_embedding_weights, b_embeddingb_embedding_weights)
首先加…
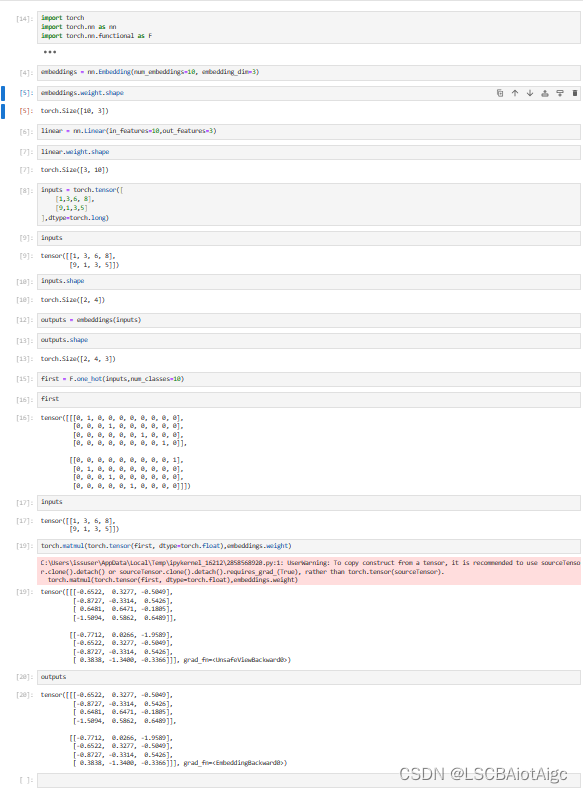
nn.Embedding()的原理
nn.Embedding()的原理:
定义一个Embedding:
embeddings nn.Embedding(num_embeddings10, embedding_dim3)vocab_size : 10
输出维度为: 3
假定输入inputs如下:
inputs torch.tensor([[1,3,6, 8],[9,1,3,5]
],dtypetorch.lo…
Embedding技术与应用(4): Embedding应用工程探析
编者按:随着互联网内容数量的急剧增长,个性化推荐已成为各大科技公司的核心竞争力之一。那么,如何构建一个可靠、高效的基于嵌入技术的推荐系统,使其能够在实际生产环境中正常运行呢?这是所有从业者都关心的问题。 本文…

(初研) Sentence-embedding fine-tune notebook
由于工作需要,需要对embedding模型进行微调,我调用了几种方案,都比较繁琐。先记录一个相对简单的方案。以下内容并不一定正确,请刷到的大佬给予指正,不胜感激!!!
一.对BGE模型&…

微调您的Embedding模型以最大限度地提高RAG管道中的相关性检索
英文原文地址:https://betterprogramming.pub/fine-tuning-your-embedding-model-to-maximize-relevance-retrieval-in-rag-pipeline-2ea3fa231149
微调您的Embedding模型以最大限度地提高RAG管道中的相关性检索
微调嵌入前后的 NVIDIA SEC 10-K 文件分析
2023 年…
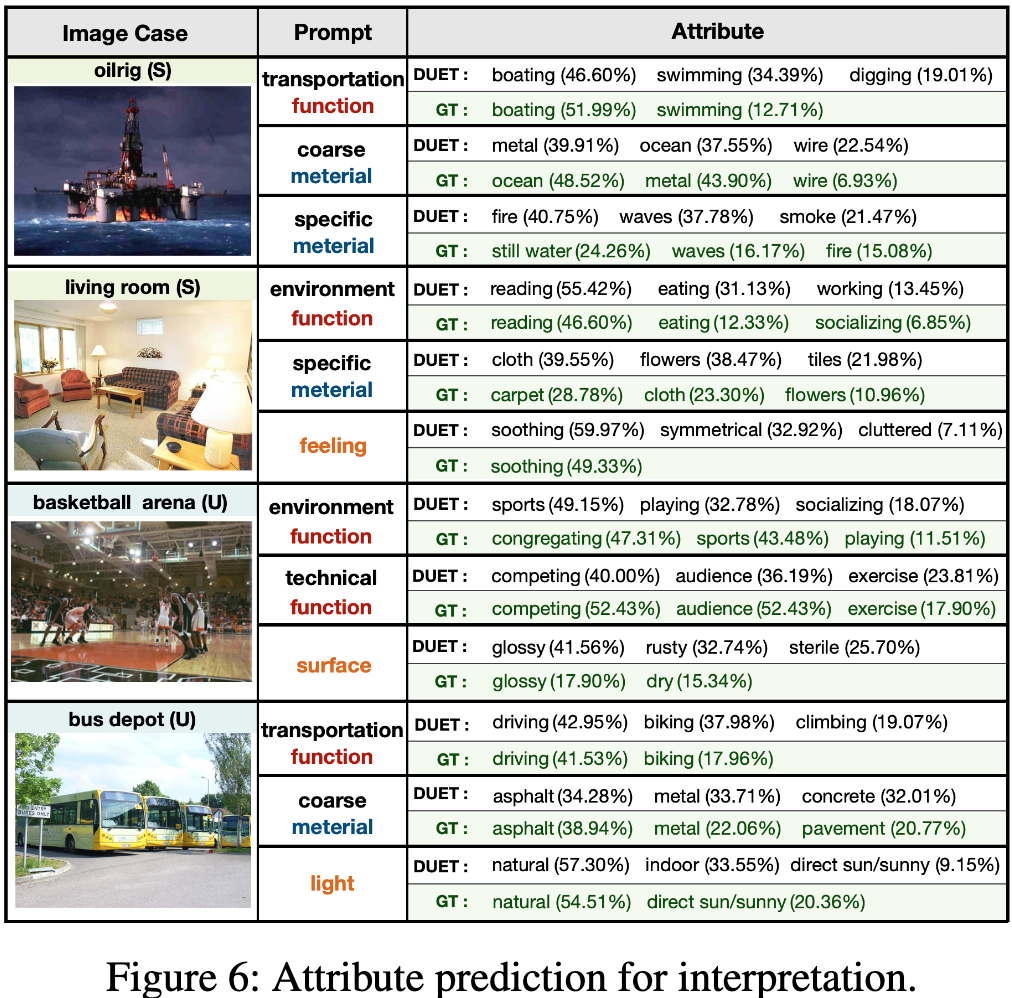
AAAI 2023 | 语言模型如何增强视觉模型的零样本能力 ?
文章链接:https://arxiv.org/abs/2207.01328 项目地址:https://github.com/zjukg/DUET 该论文设计了一种新的零样本学习范式,通过迁移语言模型中的先验语义知识,与视觉模型的特征感知能力进行对齐,以增强后者对于未见过…
如何实现TensorFlow自定义算子?
在上一篇文章中 Embedding压缩之基于二进制码的Hash Embedding,提供了二进制码的tensorflow算子源码,那就顺便来讲下tensorflow自定义算子的完整实现过程。
前言
制作过程基于tensorflow官方的custom-op仓库以及官网教程,并且在Ubuntu和Mac…
onehot-词嵌入-图嵌入
目录
一、为什么要有词嵌入?
二、one-hot编码:
三、什么是词嵌入(word embedding)
1、什么是嵌入矩阵?
2、为什么要设置维数?
3、相比one-hot编码的优点
4、什么是word2vec和GLove?
四、…
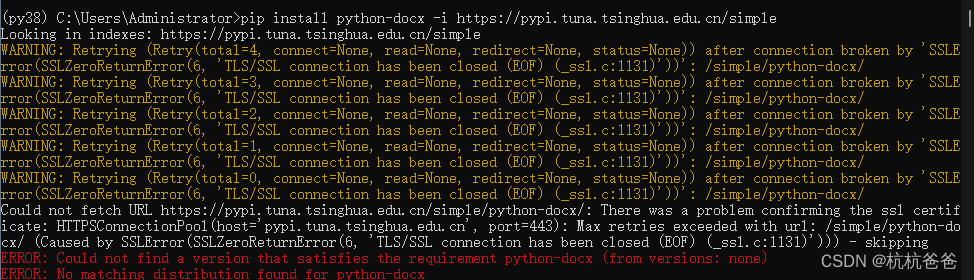
Embedding 向量生成GPT数据使用相关
如果使用python3.6的版本,使用pycharm创建工程,那么默认会使用 docx包,这样运行程序会爆异常,突然想起以前请教的一个大神,想当 初,这个问题困扰了我 两天时间,在此记录一下:
pytho…

【nlp】3.2 Transformer论文复现:1. 输入部分(文本嵌入层和位置编码器)
Transformer论文复现:输入部分(文本嵌入层和位置编码器) 1 输入复现1.1 文本嵌入层1.1.1 文本嵌入层的作用1.1.2 文本嵌入层的代码实现1.1.3 文本嵌入层中的注意事项1.2 位置编码器1.2.1 位置编码器的作用1.2.2 位置编码器的代码实现1.2.3 位置编码器中的注意事项1 输入复现…
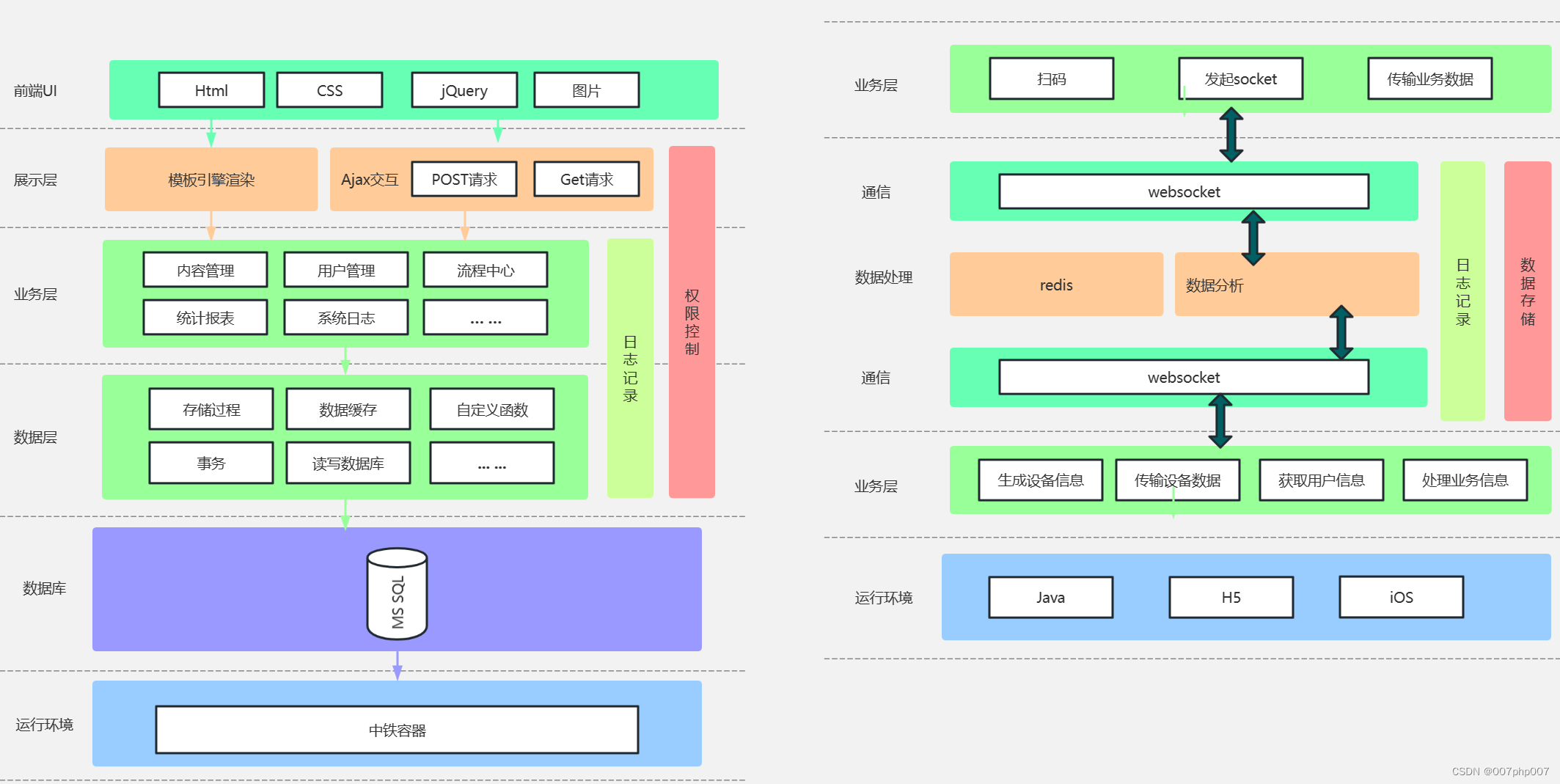
通知中心架构:打造高效沟通平台,提升信息传递效率
随着信息技术的快速发展,通知中心架构作为一种关键的沟通工具,正逐渐成为各类应用和系统中必不可少的组成部分。本文将深入探讨通知中心架构的意义、设计原则以及在实际场景中的应用。
### 什么是通知中心架构?
通知中心架构是指通过集中管…
在深度学习中,端到端的含义
在深度学习中,端到端(End-to-End)指的是整个系统从输入到输出的完整学习过程,而不需要明确定义和手动设计中间的特征提取或处理步骤。具体而言,端到端深度学习方法强调通过一个统一的、端到端的模型,直接从…

Datawhale-chatGPT用于句词分类
NLU基础 句子级别的分类 Token级别的分类 相关API chatGPT Style prompt建议 NLU应用
文档问答 分类/实体微调 智能对话

自然语言处理从小白到大白系列(2)word Embedding从one-hot到word2vec
我们知道,对于我们的计算机来说,没有办法像人一样理解自然语言,在人工智能领域,这还有很长一段路要走,就算要直接处理自然语言,都很困难。因此,人们想办法把自然语言用数字的方式表示࿰…
LangChain - classes
文章目录 说明langchainagentscachecallbacksmemorychat_loaderschat_modelsdocstoredocument_loadersdocument_transformersembeddingsevaluationgraphsindexesllmsloadmemoryoutput_parserspromptsretrieversrunnablesschemasmithstoragetext_splittertoolsutilitiesutilsvec…
LLM大语言模型(八):ChatGLM3-6B使用的tokenizer模型BAAI/bge-large-zh-v1.5
背景
BGE embedding系列模型是由智源研究院研发的中文版文本表示模型。
可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
BAAI/BGE embedding系列模型
模型列表
ModelLanguageDescriptionq…

GPT实战系列-简单聊聊LangChain搭建本地知识库准备
GPT实战系列-简单聊聊LangChain搭建本地知识库准备 LangChain 是一个开发由语言模型驱动的应用程序的框架,除了和应用程序通过 API 调用, 还会: 数据感知 : 将语言模型连接到其他数据源 具有代理性质 : 允许语言模型与其环境交互
LLM大模型…
LLM大语言模型(六):RAG模式下基于PostgreSQL pgvector插件实现vector向量相似性检索
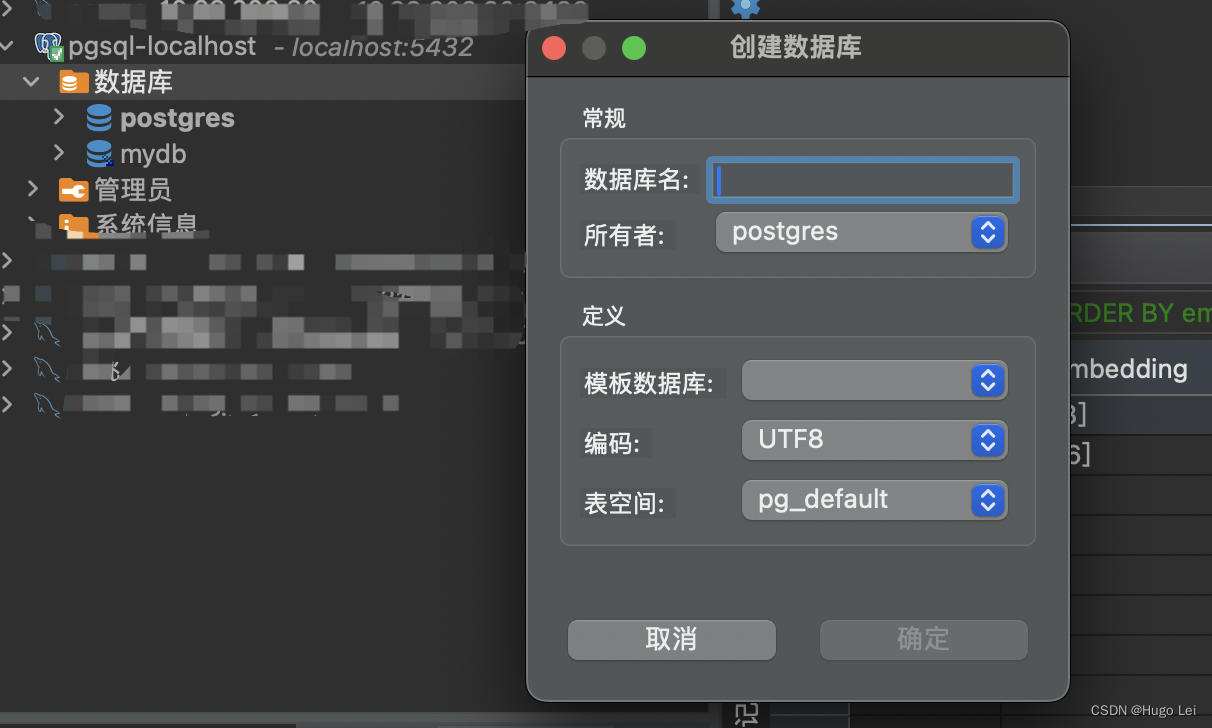
目录 HightLightMac上安装PostgreSQLDBever图形界面管理端创建DB 使用向量检索vector相似度计算近似近邻索引HNSW近似近邻索引示例 HightLight
使用PostgreSQL来存储和检索vector,在数据规模非庞大的情况下,简单高效。
可以和在线业务共用一套DB&#…

【译】矢量数据库 101 - 什么是矢量数据库?
原文地址:Vector Database 101 - What is a Vector Database?
1. 简介
大家好——欢迎回到 Milvus 教程。在上一教程中,我们快速浏览了每天产生的日益增长的数据量。然后,我们介绍了如何将这些数据分成结构化/半结构化数据和非结构化数据&…
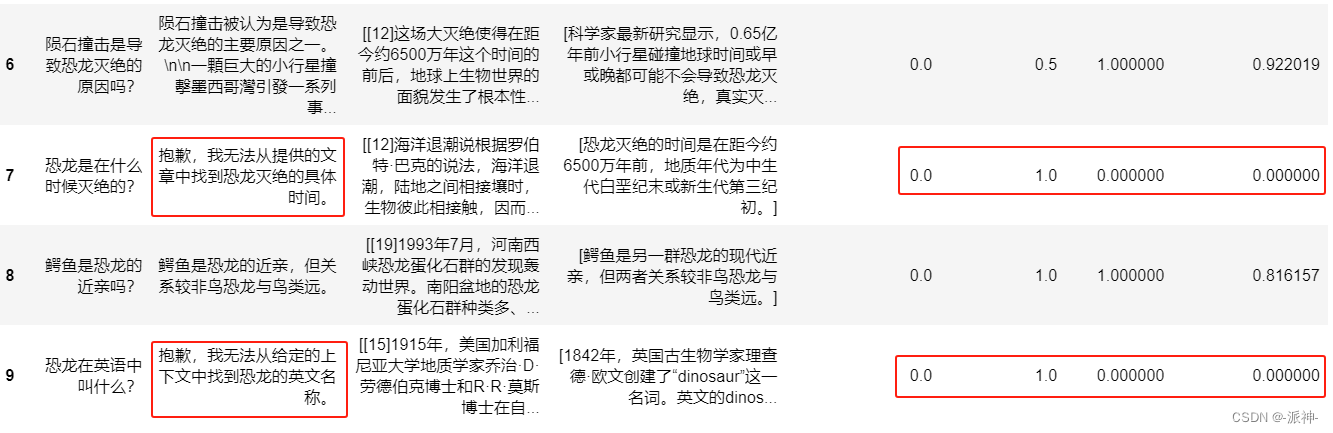
【GPT】根据embedding进行相似匹配(QA问答、redis使用)更新中
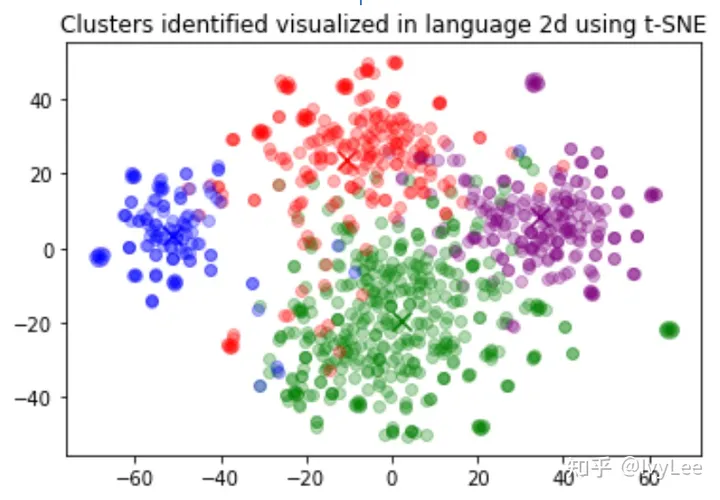
note 文章目录 note一、openai api redis的使用二、聚类和降维可视化三、推荐系统和QAReference 一、openai api redis的使用
import openai
from openai.embeddings_utils import get_embedding, cosine_similarity
from redis.commands.search.query import Query
from re…

【合合TextIn】AI构建新质生产力,合合信息Embedding模型助力专业知识应用
目录
一、合合信息acge模型获MTEB中文榜单第一
二、MTEB与C-MTEB
三、Embedding模型的意义
四、合合信息acge模型
(一)acge模型特点
(二)acge模型功能
(三)acge模型优势
五、公司介绍 一、合合信息…

Transformer位置编码(Position Embedding)理解
本文主要介绍4种位置编码,分别是NLP发源的transformer、ViT、Sw-Transformer、MAE的Position Embedding 一、NLP transformer
使用的是1d的绝对位置编码,使用sincos将每个token编码为一个向量【硬编码】 Attention Is All You Need 在语言中࿰…

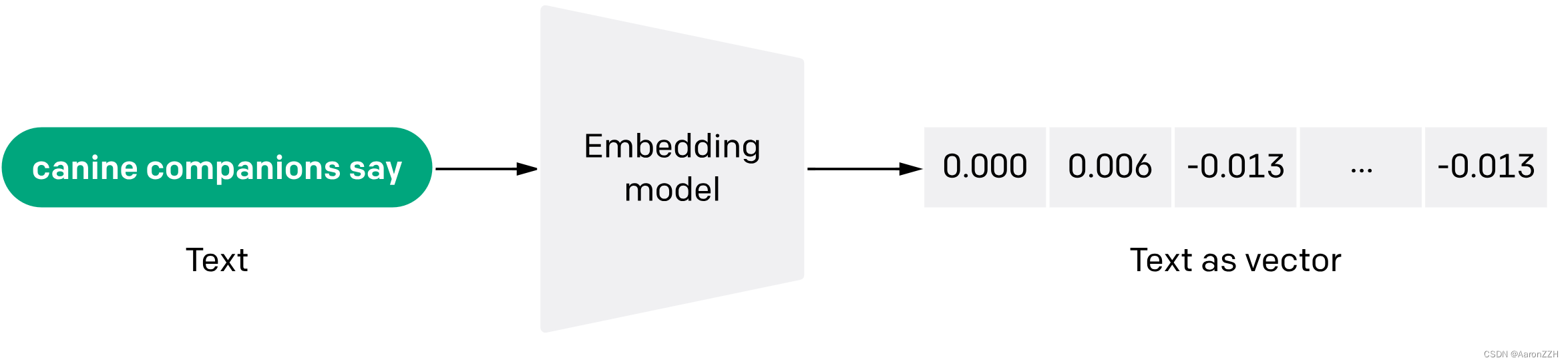
语言模型中“嵌入”(embedding)概念的介绍
嵌入(embedding)是一种尝试通过数的数组来表示某些东西“本质”的方法,其特性是“相近的事物”由相近的数表示。 1.嵌入的作用 嵌入(Embedding)是一种将高维、离散或符号形式的数据转换为低维连续向量表示的方法。这些…

2024年大模型面试准备(二):LLM容易被忽略的Tokenizer与Embedding
分词和嵌入一直是LM被忽略的一部分。随着各大框架如HF的不断完善,大家对tokenization和embedding的重视程度越来越低,到现在初学者大概只能停留在调用tokenizer.encode这样的程度了。
知其然不知其所以然是很危险的。比如你要调用ChatGPT的接口…

用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。
在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回…
高级RAG(四):RAGAs评估
之前我完成了父文档检索器和llamaIndex从小到大的检索这两篇博客,我在这两篇博客中分别介绍了使用langchain和llamaIndex进行文档检索的方法和步骤,其中包含了不同的RAG的检索策略,通常来说一个典型的RAG系统一般包含两个主要的部件ÿ…
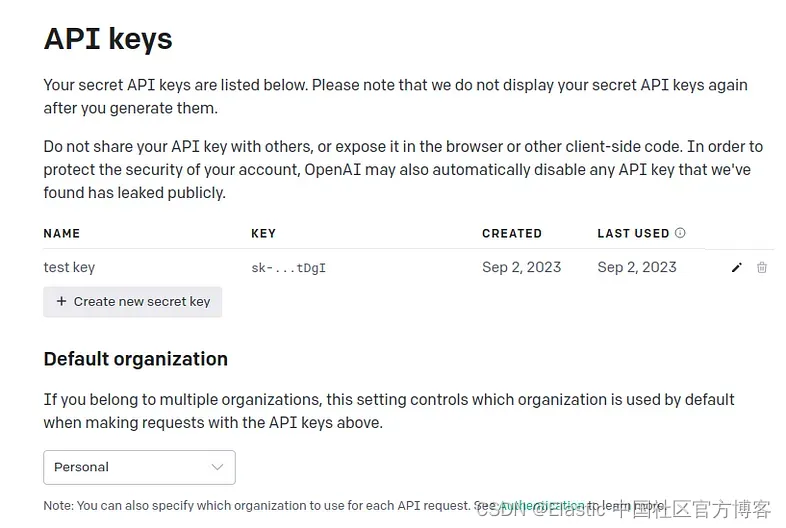
如何在 Elasticsearch 中使用 Openai Embedding 进行语义搜索
随着强大的 GPT 模型的出现,文本的语义提取得到了改进。 在本文中,我们将使用嵌入向量在文档中进行搜索,而不是使用关键字进行老式搜索。 什么是嵌入 - embedding?
在深度学习术语中,嵌入是文本或图像等内容的数字表示…
nn.Embedding详解
nn.Embedding 是 PyTorch 中的一个模块,用于将离散的单词或标签等转换成一个固定大小的连续向量,通常在处理自然语言处理任务时用于单词的向量表示。
以下是 nn.Embedding 的一些关键点以及它的参数:
作用:
nn.Embedding 层用于创建一个词…
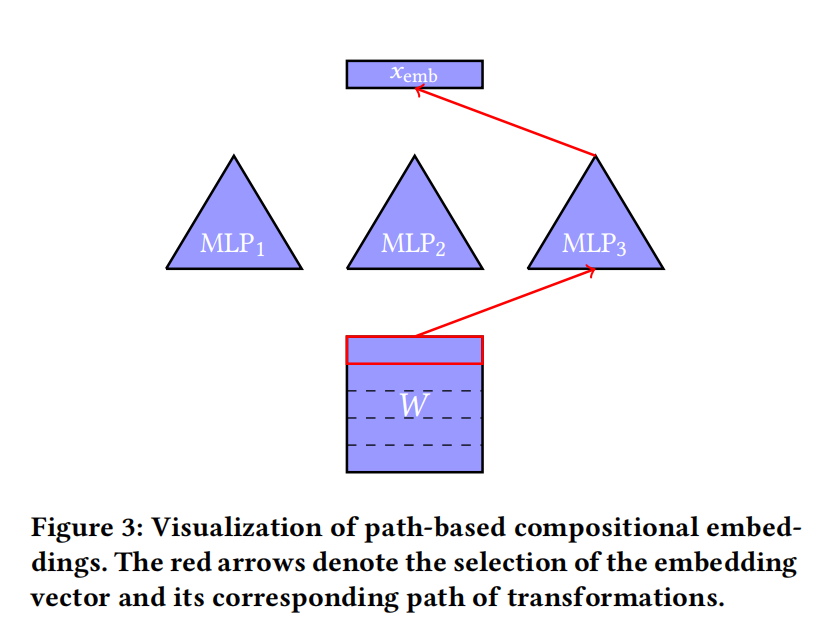
Embedding压缩之hash embedding
在之前的两篇文章 CTR特征重要性建模:FiBiNet&FiBiNet模型、CTR特征建模:ContextNet & MaskNet中,阐述了特征建模的重要性,并且介绍了一些微博在特征建模方面的研究实践,再次以下面这张图引出今天的主题&#…
LLM资料:中文embedding库
Highlight(重点提示)
理解LLM,就要理解Transformer,但其实最基础的还是要从词的embedding讲起。
毕竟计算机能处理的只有数字,所以万事开头的第一步就是将要处理的任务转换为数字。 面向中文的开源embedding库在自然…

OpenAI ChatGPT API 文档之 Embedding
译者注:
Embedding 直接翻译为嵌入似乎不太恰当,于是问了一下 ChatGPT,它的回复如下: 在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称…
go |struct embedding、generics、goroutine
go 的结构内嵌 注意点,有点像js func main() {fmt.Println("hello zhangbuda...")// 这个内嵌 和 js 有点像co : container{base: base{num: 22,},str: "zhangdbau hahahahah ",}fmt.Println("co: ", co)/*在 Go 语言中,如…
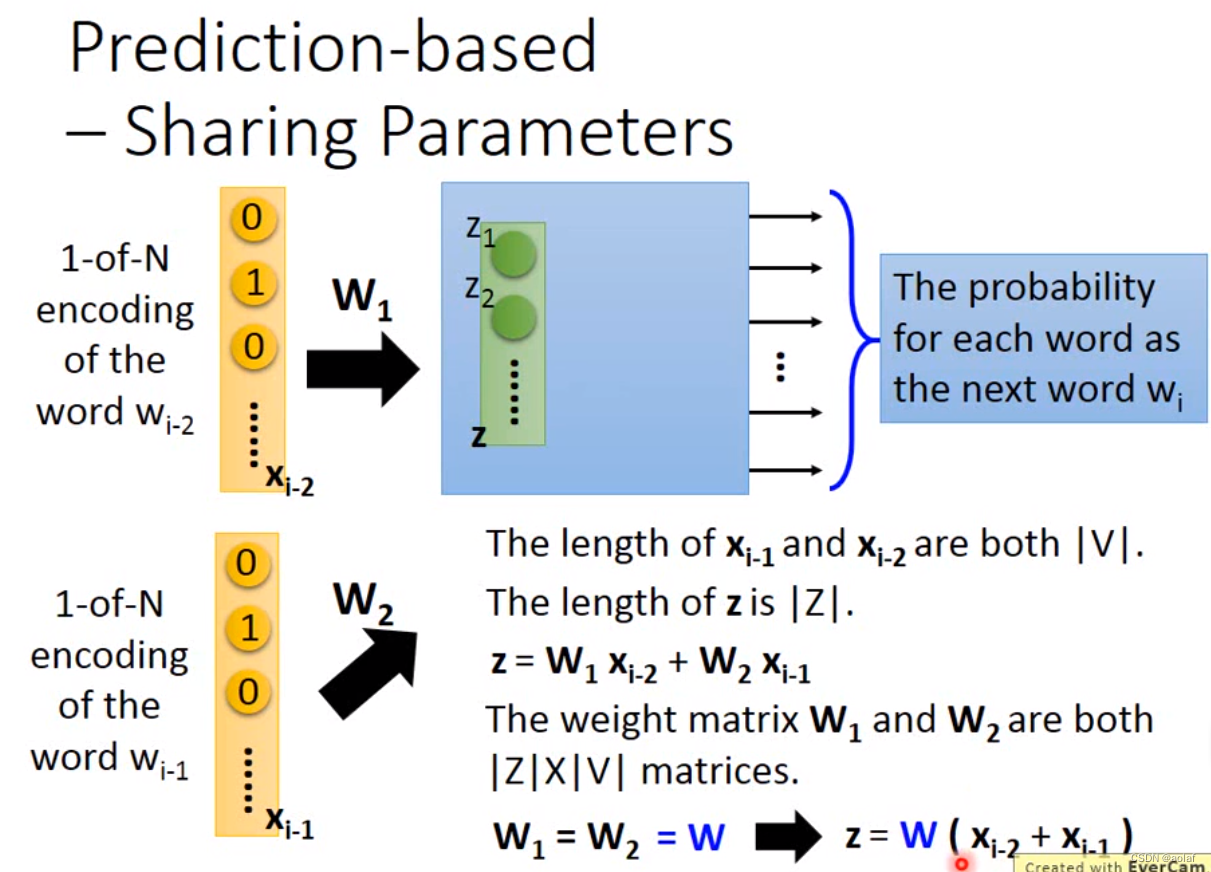
多模态基础--- word Embedding
1 word Embedding
原始的单词编码方式: one-hot,维度太大,不同单词之间相互独立,没有远近关系区分。 wordclass,将同一类单词编码在一起,此时丢失了类别和类别间的相关信息,比如class1和class3…
chatGPT2:如何构建一个可以回答有关您网站问题的 AI 嵌入(embeddings)
感觉这个目前没有什么用,因为客户可以直接问通用chatGPT,实时了解你网站内的信息,除非你的网站chatGPT无法访问。 不过自动预订、买票等用嵌入还是挺有用的。
什么是嵌入?
OpenAI的嵌入(embeddings)是一种…