之前介绍过大语言模型(LLM)相关技术 RAG(Retrieval Augmented Generation)的内容,但随着 LLM 技术的发展,越来越多的高级 RAG 检索方法也随之被人发现,相对于普通的 RAG 检索,高级 RAG 通过更深化的技术细节、更复杂的搜索策略,提供出了更准确、更相关、更丰富的信息检索结果。
今天我们就来介绍一下高级 RAG 检索策略其中的一种方法——句子窗口检索。
句子窗口检索介绍
在介绍句子窗口检索之前,我们先简单介绍一下普通的 RAG 检索,下面是普通 RAG 检索的流程图:

-
先将文档切片成大小相同的块
-
将切片后的块进行 Embedding 并保存到向量数据库
-
根据问题检索出 Embedding 最相似的 K 个文档库
-
将问题和检索结果一起交给 LLM 生成答案
普通 RAG 检索的问题是如果文档切片比较大的话,检索结果可能会包含很多无关信息,从而导致 LLM 生成的结果不准确。我们再来看下句子窗口检索的流程图:
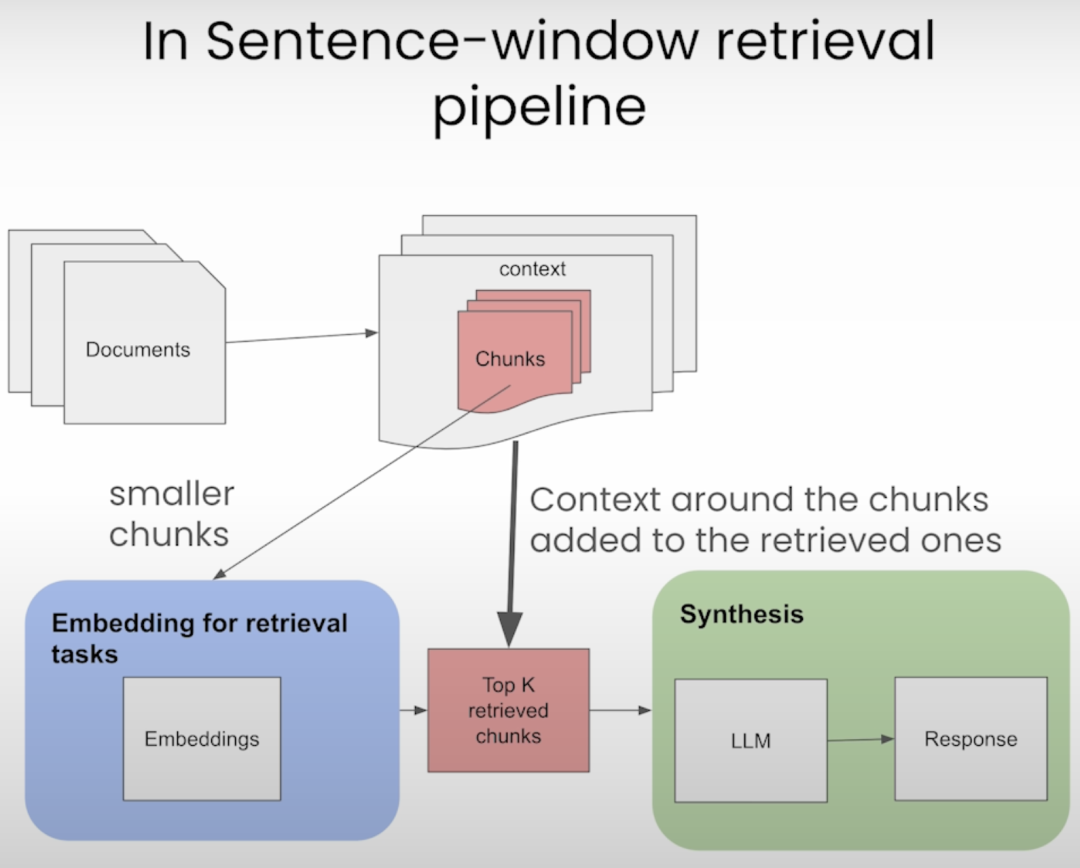
-
和普通 RAG 检索相比,句子窗口检索的文档切片单位更小,通常以句子为单位
-
在检索时,除了检索到匹配度最高的句子,还将该句子周围的上下文也作为检索结果一起提交给 LLM
句子窗口检索让检索内容更加准确,同时上下文窗口又能保证检索结果的丰富性。
原理
句子窗口检索的原理其实很简单,首先在文档切分时,将文档以句子为单位进行切分,同时进行 Embedding 并保存数据库。然后在检索时,通过问题检索到相关的句子,但并不只是将检索到的句子作为检索结果,而是将该句子前面和后面的句子一起作为检索结果,包含的句子数量可以通过参数来进行设置,最后将检索结果再一起提交给 LLM 来生成答案。

我们再通过示例代码来理解句子窗口检索的原理,在 RAG 框架中,LlamaIndex[1]很好地实现了句子窗口检索的功能,下面我们就用 LlamxIndex 来演示句子窗口检索的功能。
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.schema import Document
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
text = "hello. how are you? I am fine! Thank you. And you? I am fine too. "
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
-
使用 SentenceWindowNodeParser 创建一个文档解析器,设置
window_size为 3,这意味着句子窗口最多会包含 7 个句子,包括检索到的句子前面 3 个句子、检索到的句子本身以及检索到的句子后面 3 个句子 -
使用文档解析器对文档进行解析,解析后的结果会包含
window和original_text两个元数据 -
window_metadata_key是指保存句子窗口包含的所有句子的键值,而original_text_metadata_key是指检索到的句子的键值 -
最后通过文档解析器将原始文档进行解析
注意:在之前的版本,句子窗口只会添加检索到的句子后面 2 个句子,也就是说在默认window-size=3的情况下,句子窗口总共只会包含 6 个句子,但新版本将核心功能提取成llama-index-core后,句子窗口会将检索到的句子后面的 3 个句子作为窗口,更多的信息可以查看官方仓库代码[2]。
我们再来看解析后的 nodes 中的内容,首先我们看第一个 node:
print(nodes[0].metadata)
# 显示结果
{'window': 'hello. how are you? I am fine! Thank you. ', 'original_text': 'hello. '}
可以看到当检索到的句子是第 1 个句子时,因为该句子前面没有其他句子,所以句子窗口总共包含了 4 个句子,也就是检索到的句子本身再加上后面的 3 个句子。
print(nodes[3].metadata)
# 显示结果
{'window': 'hello. how are you? I am fine! Thank you. And you? I am fine too. ', 'original_text': 'Thank you. '}
当检索到的句子是第 4 个句子时,句子窗口就会包含检索到的句子前 3 个句子、检索到的句子本身以及检索到的句子后面 3 个句子,但因为后面只有 2 个句子,所以总共就只有 6 个句子。
中文句子切分
句子窗口解析器一般以英文中句子结束的标点符号来切分句子,默认的标点符号有.?!等,但如果是中文的话,这种切分方式就会失效,但我们可以在文档解析器中增加解析规则参数来解决这个问题:
import re
def sentence_splitter(text):
nodes = re.split("(?<=。)|(?<=?)|(?<=!)", text)
nodes = [node for node in nodes if node]
return nodes
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
sentence_splitter=sentence_splitter,
)
我们增加了sentence_splitter参数,并传入自定义的sentence_splitter函数,这个函数的作用就是将文档按照中文标点符号进行切分。
text = "你好。你好吗?我很好!谢谢。你呢?我也很好。"
print(nodes[0].metadata)
print(nodes[3].metadata)
# 显示结果
{'window': '你好。你好吗?我很好!谢谢。', 'original_text': '你好。'}
{'window': '你好。你好吗?我很好!谢谢。你呢?我也很好。', 'original_text': '谢谢。'}
可以看到,替换了解析规则后,解析器解析出来的句子和英文解析时的效果是一样的。
句子窗口使用
下面我们再来看看句子窗口检索在实际 RAG 项目中的使用,文档数据我们还是使用之前维基百科上的复仇者联盟[3]电影剧情来进行测试。
普通 RAG 检索示例
首先我们看下普通 RAG 检索在文档切分和检索时的效果:
from llama_index.core import SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.settings import Settings
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
documents = SimpleDirectoryReader("./data").load_data()
text_splitter = SentenceSplitter()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
embed_model = OpenAIEmbedding()
Settings.llm = llm
Settings.embed_model = embed_model
Settings.node_parser = text_splitter
base_index = VectorStoreIndex.from_documents(
documents=documents,
)
base_engine = base_index.as_query_engine(
similarity_top_k=2,
)
-
我们使用 LlamaIndex 创建了一个普通 RAG 检索,首先从
data目录中加载文档 -
使用
SentenceSplitter作为文档解析器对文档进行解析,与默认的TokenTextSplitter不同,SentenceSplitter切分后的块一般会包含完整的句子,而不会出现部分句子的情况 -
使用 OpenAI 的 Embedding 和 LLM 模型进行文档 Embedding 和生成答案,LlamaIndex 最新版本使用了
Setting参数来代替原来的ServiceContext -
最后创建一个查询引擎,只获取相关度最高的 2 个文档作为检索结果
再来看测试的结果:
question = "奥创是由哪两位复仇者联盟成员创造的?"
response = base_engine.query(question)
print(f"response: {response}")
print(f"len: {len(response.source_nodes)}")
text = response.source_nodes[0].node.text
print("------------------")
print(f"Text: {text}")
text = response.source_nodes[1].node.text
print("------------------")
print(f"Text: {text}")
# 显示结果
response: 奥创是由托尼·斯塔克和布鲁斯·班纳这两位复仇者联盟成员创造的。
len: 2
---------------
-
普通 RAG 检索的答案是正确的,因为检索到文档中包含了与答案相关的内容
-
普通 RAG 检索的相关文档有 2 个,按照相似度进行了排序
句子窗口检索示例
我们再来看看句子窗口检索在项目中的效果:
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.indices.postprocessor import MetadataReplacementPostProcessor
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
documents = SimpleDirectoryReader("./data").load_data()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
embed_model = OpenAIEmbedding()
Settings.llm = llm
Settings.embed_model = embed_model
Settings.node_parser = node_parser
sentence_index = VectorStoreIndex.from_documents(
documents=documents,
)
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=2, node_postprocessors=[postproc]
)
-
句子窗口检索的代码与普通 RAG 检索有一些差别,第一个不同点是使用了
SentenceWindowNodeParser来作为文档解析器,这个我们之前已经介绍过了 -
第二个不同点是使用了
MetadataReplacementPostProcessor来对检索结果进行后处理,将检索结果替换成window这个元数据的值
测试结果如下:
response = sentence_window_engine.query(question)
print(f"response: {response}")
print(f"len: {len(response.source_nodes)}")
window = response.source_nodes[0].node.metadata["window"]
sentence = response.source_nodes[0].node.metadata["original_text"]
print("------------------")
print(f"Window: {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
window = response.source_nodes[1].node.metadata["window"]
sentence = response.source_nodes[1].node.metadata["original_text"]
print("------------------")
print(f"Window : {window}")
print("------------------")
print(f"Original Sentence: {sentence}")
# 显示结果
response: 奥创是由托尼·斯塔克和布鲁斯·班纳创造的。
len: 2
---------------
-
句子窗口检索的答案也是正确的,但可以看到检索到的文档要比普通 RAG 检索的少
-
句子窗口的句子数量跟我们之前介绍的一样,包括
Original Sentence句子的前面 3 个句子,Original Sentence句子本身以及Original Sentence句子后面的 3 个句子
检索效果对比
经过上面示例代码的测试,我们可以看到普通 RAG 检索和句子窗口检索都可以获取到正确答案,但看不出具体哪种检索效果更好,我们可以使用之间介绍过的 LLM 评估工具Trulens[4]来做两者的效果对比。
from trulens_eval import Tru, Feedback, TruLlama
from trulens_eval.feedback.provider.openai import OpenAI as Trulens_OpenAI
from trulens_eval.feedback import Groundedness
tru = Tru()
openai = Trulens_OpenAI()
def rag_evaluate(query_engine, eval_name):
grounded = Groundedness(groundedness_provider=openai)
groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons, name="Groundedness")
.on(TruLlama.select_source_nodes().node.text)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
qa_relevance = Feedback(
openai.relevance_with_cot_reasons, name="Answer Relevance"
).on_input_output()
qs_relevance = (
Feedback(openai.qs_relevance_with_cot_reasons, name="Context Relevance")
.on_input()
.on(TruLlama.select_source_nodes().node.text)
)
tru_query_engine_recorder = TruLlama(
query_engine,
app_id=eval_name,
feedbacks=[
groundedness,
qa_relevance,
qs_relevance,
],
)
with tru_query_engine_recorder as recording:
query_engine.query(question)
-
定义了评估方法,方法参数是检索引擎
query_engine和评估名称eval_name -
使用 Trulens 的
groundedness,qa_relevance和qs_relevance对 RAG 检索结果进行评估
关于 Trulens 更多信息可以参考我之前的文章,下面我们运行评估方法:
tru.reset_database()
rag_evaluate(base_engine, "base_evaluation")
rag_evaluate(sentence_window_engine, "sentence_window_evaluation")
Tru().run_dashboard()
Trulens 的 web 页面如下所示,我们可以看到句子窗口检索并不是每一项结果都比普通 RAG 检索要好,有时候甚至会比普通 RAG 检索的效果要差,这就需要我们通过进一步优化来让句子窗口检索的效果更好,比如设置window_size的大小等等。
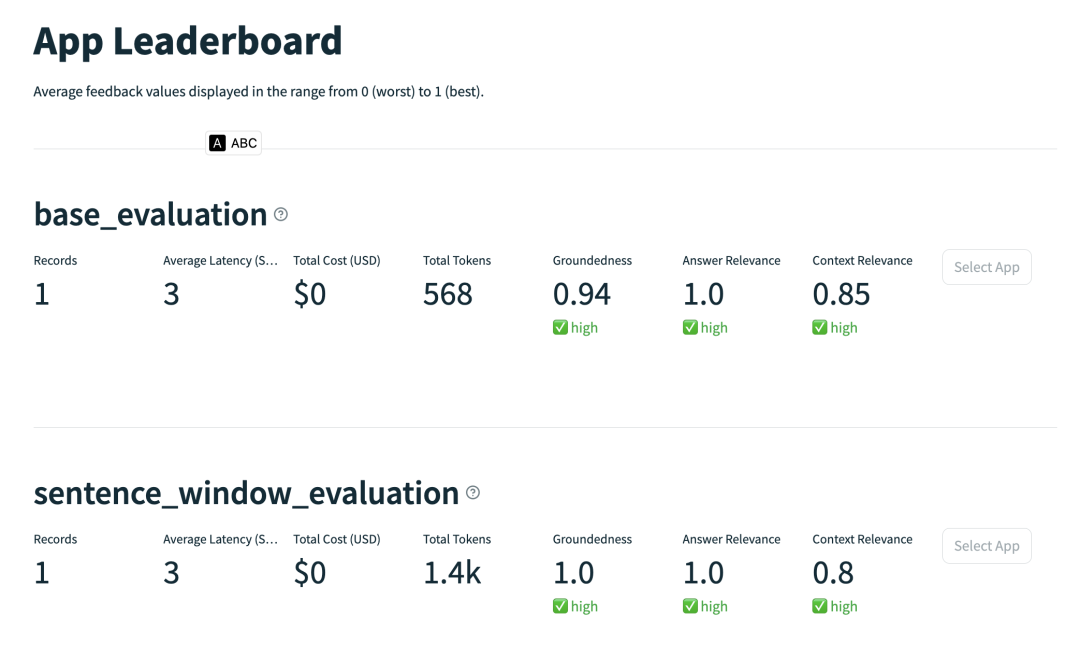
总结
RAG 虽然可以解决 LLM 应用中的大部分问题,但它不是银弹,高级 RAG 检索更加不是能解决所有 RAG 问题的方法,还是需要在具体项目中根据需求来确认使用哪种检索方法,并通过调整参数、优化文档等方法来不断优化我们的 RAG 应用效果。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1] LlamaIndex: https://www.llamaindex.ai/
[2]官方仓库代码: https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/node_parser/text/sentence_window.py#L101
[3]复仇者联盟: https://en.wikipedia.org/wiki/Avenger
[4]Trulens: https://www.trulens.org/




