一、目标函数
今天要讨论的是以下三种模型结构:
Decoder-only模型:例如,GPT-3,单向上下文嵌入,在生成文本时一次生成一个token
Encoder-only模型:例如,BERT,利用双向上下文注意力生成embeding
Encoder-decoder模型:例如,T5,利用双向上下文编码,利用单向上下文生成文本
最终结果就是将token序列映射为一个Embedding向量
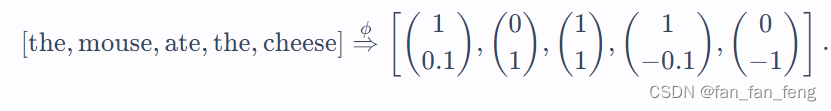
其中:
L :代表文本长度
d:代表embeding向量的维度
1.1 Decoder-only 模型
自回归语言模型预测是一个条件分布:即根据1,2,。。。i-1个词语,去预测第1个词语是什么
公式为: =
那格局最大似然原理(通俗点讲就是,找到一个参数,是的概率最大),定义以下负对数似然目标函数:
1.2 Encoder-only模型
Decoder-only模型,它会产生(单向)上下文嵌入,更适合文本生成任务
Encoder-only模型,他是双向上下文嵌入,更适合分类任务
1.2.1 Bert 模型
BERT的目标函数,它包含以下两个部分:
- 掩码语言模型(Masked language modeling)
- 下一句预测(Next sentence prediction)
其中有两个特殊的token:
- [CLS] :包含用于驱动分类任务的嵌入,即Next sentence prediction 任务
- [SEP] :用于告诉模型区分第一个序列(例如,前提)与第二个序列(例如,假设)。
1.2.1.1 掩码语言模型
基本思想是通过加噪然后预测来进行训练:
[the,[MASK],ate,[MASK],cheese] ⇒ [the,mouse,ate,the,cheese]
需要模型把[MASK]位置的词语给预测出来
噪声函数的定义:
- 假设 I⊂{1,…,L} 代表所有位置中随机的15%。
- 对于每个 i∈I,(x~i 代表需要mask的位置):
- 以0.8的概率, x~i←[MASK]
- 以0.1的概率, x~i←xi
- 以0.1的概率, x~i←random word from V
1.2.2 RoBERTa
RoBERTa对BERT进行了以下改进:
- 删除了下一句预测这一目标函数(发现它没有帮助)。
- 使用更多数据训练(16GB文本 ⇒⇒ 160GB文本 )。
- 训练时间更长。
- RoBERTa在各种基准上显著提高了BERT的准确性(例如,在SQuAD上由81.8到89.4)。
1.3 Encoder-Decoder模型:
- 首先像BERT一样对输入进行双向编码。
- 然后像GPT-2一样对输出进行自回归解码。
1.3.1 BART(Bidirectional Auto-Regressive Transformers)
BART (Lewis et al. 2019)是基于Transformer的编码器-解码器模型。
- 使用与RoBERTa相同的编码器架构(12层,隐藏维度1024)。
- 使用与RoBERTa相同的数据进行训练(160GB文本)。
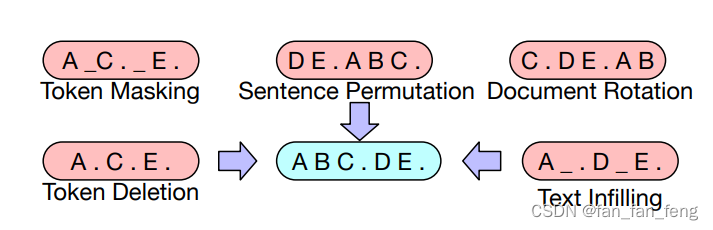
基于BERT的实验,最终模型进行以下了变换:
- 掩码文档中30%的token
- 将所有子句打乱
最后,通过微调,BART在分类和生成任务上都展示了强大的效果。
1.3.2 T5(Text-to-Text Tranfer Transformer)
训练过程:给定一段文本,在随机位置将其分割为输入和输出:
T= {the,mouse ,ate ,the ,cheese}
X1 = {the} Y1 = {mouse,ate,the,cheese}
X2 = {the,mouse} Y2= {ate,the,cheese}
X3 = {the ,mouse,ate} Y3= {the,cheese}
差异:
- BERT使用 [CLS][CLS] 的嵌入来预测。
- T5、GPT-2、GPT-3等(生成模型)将分类任务转换成自然语言生成。
二、大模型参数优化算法
2.1 随机梯度下降 (SGD)

2.2 Adam( adaptive moment estimation)
引入了一阶动量和二阶动量的概念
参数跟新过程:

说明:
学习率
一阶指数移动平滑加权
二阶指数移动平滑加权
一阶指数移动加权衰减系数
二阶指数皮冻加权衰减系数
内存占用:
之前SGD训练时只需要保存 (,
) 是模型参数的2倍
现在Adam训练要保存(,
,
,
) 是模型参数的4倍
2.3 混合半精度训练
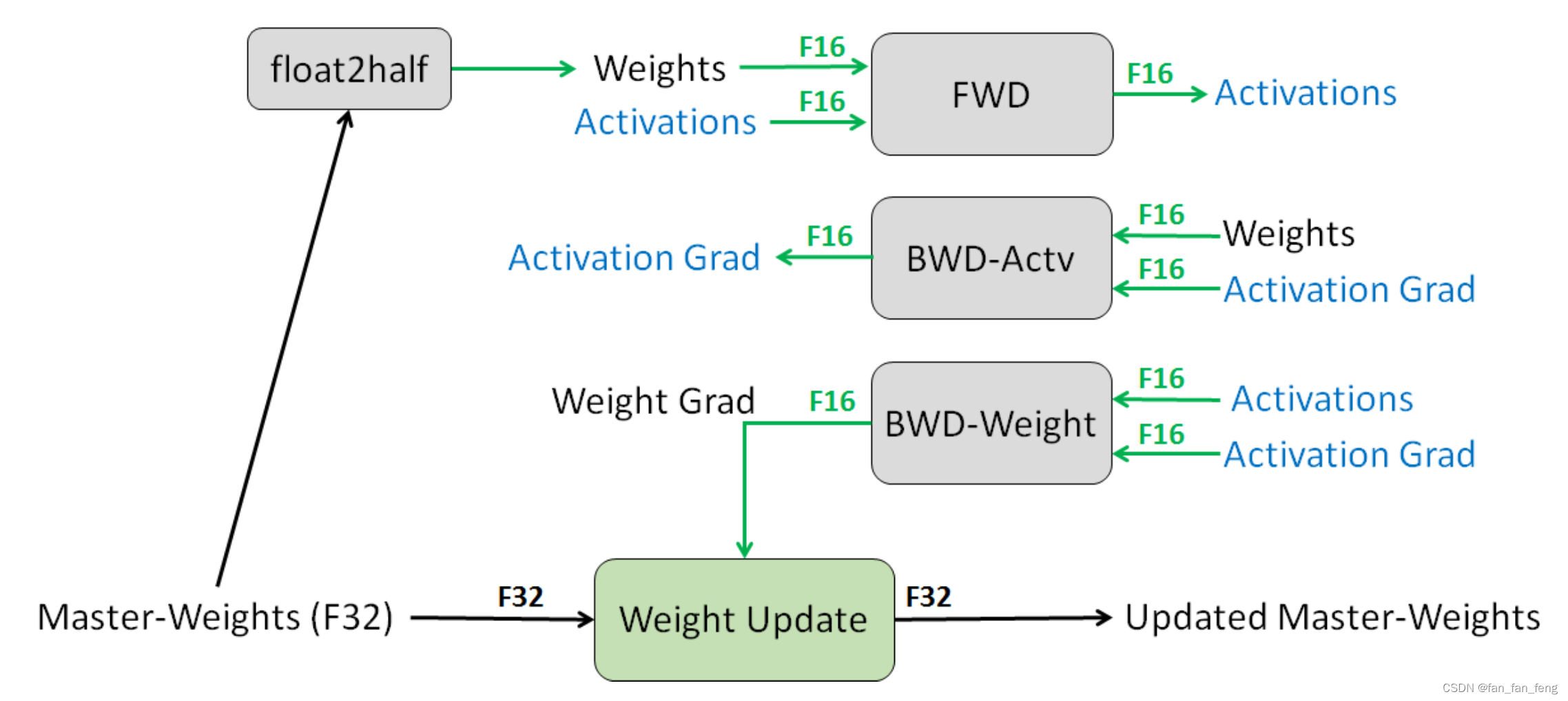
简单理解就是:
训练的时候用F16,跟新模型参数的时候用F32
2.4 学习率
2.5 参数初始化
- 给定矩阵W∈Rm×n ,标准初始化(即,xavier初始化)为 Wij∼N(0,1/n) 。
- GPT-2和GPT-3通过额外的 1/N 缩放权重,其中 N 是残差层的数量。
- T5将注意力矩阵增加一个1/d (代码)。
以GPT-3为例,使用的参数如下: