PET-TC(B)
paper b: 2020.9 It’s not just size that matters: Small language models are also few-shot learners.
Prompt: 多字完形填空式人工Prompt
Task:Text Classification
Model: Albert-xxlarge-v2
Take Away: 支持多字的完形填空Prompt,效果超越GPT3
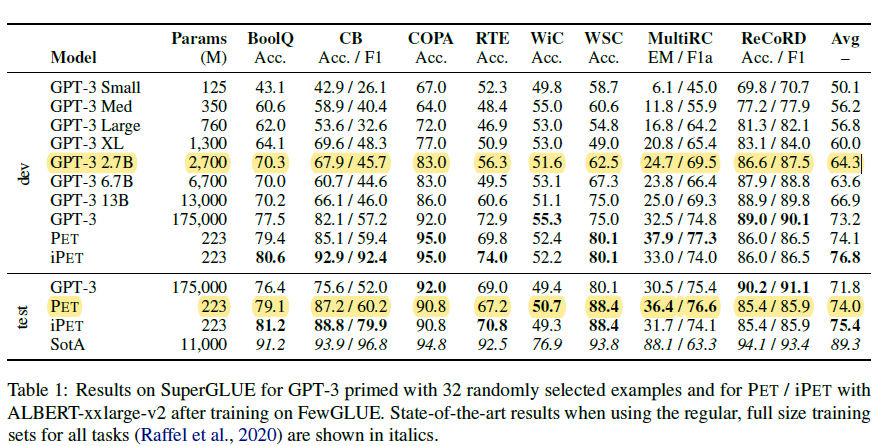
这篇paper和上面的PET-TC是同一作者,算是上文的续作,主要优化了Answer词单token设定,支持多个token作为标签词,不过限制性依旧较强是预先设定任务最大的token数,然后使用最大token数作为MASK数量,而非动态的任意数量的MASK填充。
论文对推理和训练中的多MASK填充做了不同的处理。在推理中需要向前传导K次,如下图所示
-
使用标签最大的label词长度K,生成k个MASK位置
-
对K个位置同时预估得到K个预估词,选取概率最高的1个词进行填充
-
针对填充后的新文本,对剩余K-1个位置再进行预估
-
直到所有位置都被填充,分类概率由所有填充标签词的概率累乘得到
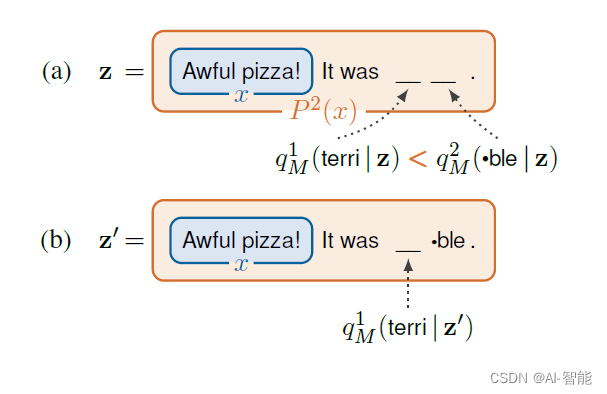
在训练过程中为了提升效率,论文使用了一次向前传导对多个位置同时完成预估,这时MASK长度是所有标签的最大长度。例如情感分类问题terr##ble长度为2,great长度为1,这时MASK填充长度为2,great只取第一个MASK词的概率,后面的忽略,概率计算如下
p(Y=−1|x)=P1M(ble|x)∗P2M(terri|~x)p(Y=1|x)=P1M(great|x)
其他部分和PET基本一样这里不再重复。效果上这篇论文换成了Albert-xxlarge-v2模型和GPT-3 few-shot在superGLUE上进行效果对比。不过以下参数对比并不太合理,虽然Albert是层共享参数,但是推理速度并无提升,12层的xxlarge模型参与计算的参数量级应该是223M*12~2B,所以并不是严格意义上的小模型。调整参数后,32个小样本上PET的效果也是超过同等量级甚至更大的GPT3在few-shot上的效果的
LM-BFF
paper: 2020.12 Making Pre-trained Language Models Better Few-shot Learners
Prompt: 完形填空自动搜索prompt
Task: Text Classification
Model: Bert or Roberta
Take Away: 把人工构建prompt模板和标签词优化为自动搜索
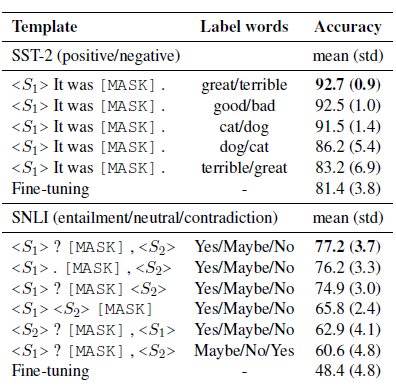
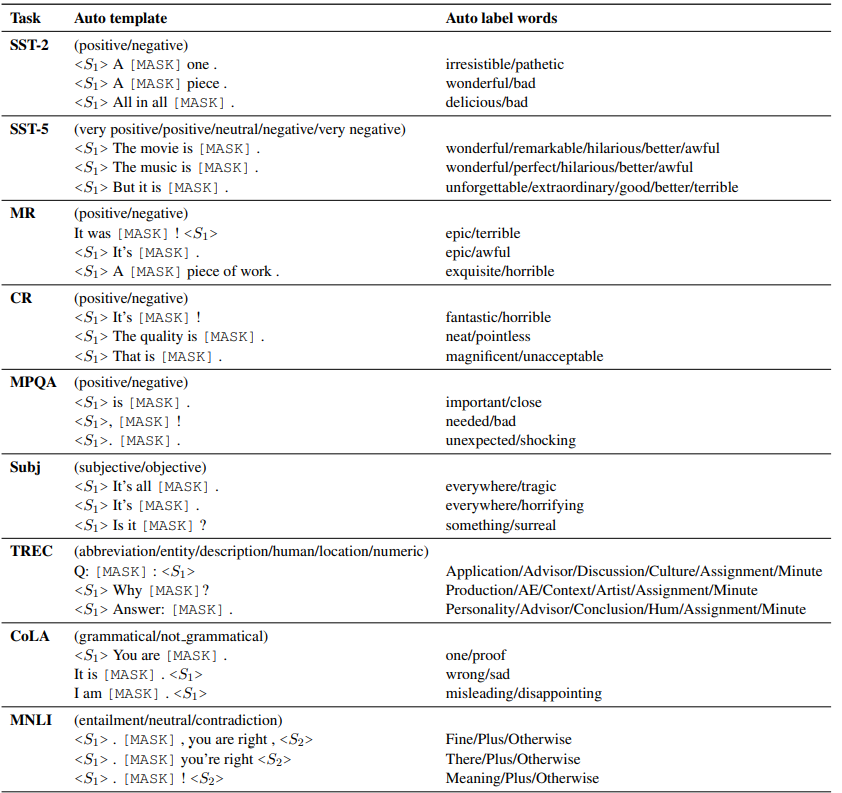
LM-BFF是陈丹琦团队在20年底提出的针对few-shot场景,自动搜索模板和触发词的Prompt方案,prompt模板延续了PET的完型填空形式,把人工构建prompt和标签词的构建优化成了自动搜索。论文先是验证了相同模板不同标签词,和相同标签词不同模板对模型效果都有显著影响,如下
以下介绍自动搜索的部分
标签词搜索
考虑在全vocab上搜索标签词搜索空间太大,在少量样本上直接微调选择最优的标签词会存在过拟合的问题。作者先通过zero-shot缩小候选词范围,再通过微调选择最优标签词。
如下,固定prompt模板(L),作者用训练集中每个分类(c)的数据,在预训练模型上分别计算该分类下MASK词的概率分布,选择概率之和在Top-k的单词作为候选词。再结合所有分类Top-K的候选词,得到n个标签词组合。这里的n和k都是超参,在100~1000不等。
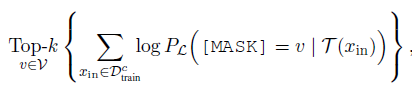
然后在n个候选标签词组合中,针对微调后在验证集的准确率,选择效果最好的标签词组合。
prompt模板搜索
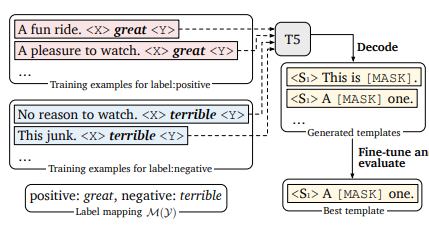
固定标签词,作者使用T5来进行模板生成,让T5负责在标签词前、后生成符合上下文语义的prompt指令,再在所有训练样本中选择整体表现最优的prompt模板。
如下, 固定二分类的标签词是great和terrible,T5的模型输入为Input+MASK+标签对应标签词+MASK,让模型来完成对MASK部分的填充。现在预训练模型中通过Beam-Search得到多个模板,再在下游任务中微调得到表现最好的一个或多个prompt模板
以上自动搜索prompt和标签词得到的部分结果如下,该说不说这种方案得到的标签词,至少直观看上去比AutoPrompt合(人)理(类)不(能)少(懂):
固定prompt微调LM

经过以上搜素得到最优标签词组合和prompt模板后,作者的微调过程模仿了GPT3的few-shot构建方式。如上图,先把输入填充进prompt模板,再从各个分类中各采样1个样本作为指令样本拼接进输入,为待预测文本补充更丰富的上下文,一起输入模型。在训练和推理时,补充的指令样本都是从训练集中采样。
同时为了避免加入的指令样本和待预测样本之间差异较大,导致模型可能直接无视接在prompt后面的指令样本,作者使用Sentence-Bert来筛选语义相似的样本作为指令样本。
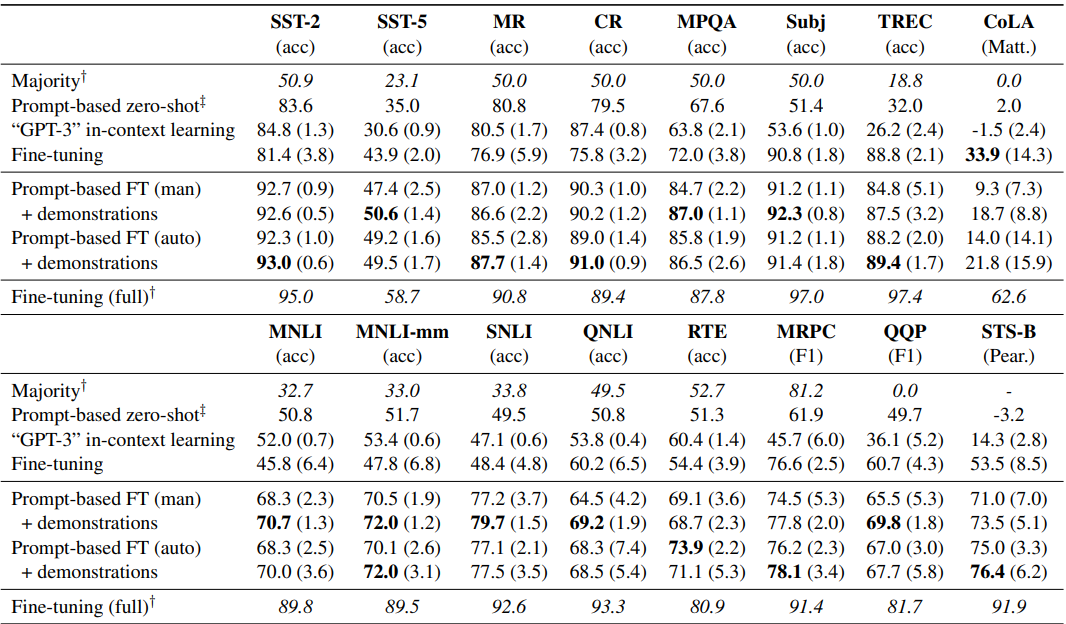
效果上,作者给出了每类采样16个样本的小样本场景下, Roberta-Large的效果,可以得到以下insights
-
部分场景下自动模板是要优于手工模板的,整体上可以打平,自动搜索是人工成本的平价替代
-
加入指令样本对效果有显著提升
-
在16个样本的few-shot场景下,prompt微调效果是显著优于常规微调和GPT3 few-shot效果的