【LangChain学习之旅】—(3) LangChain快速构建本地知识库的智能问答系统
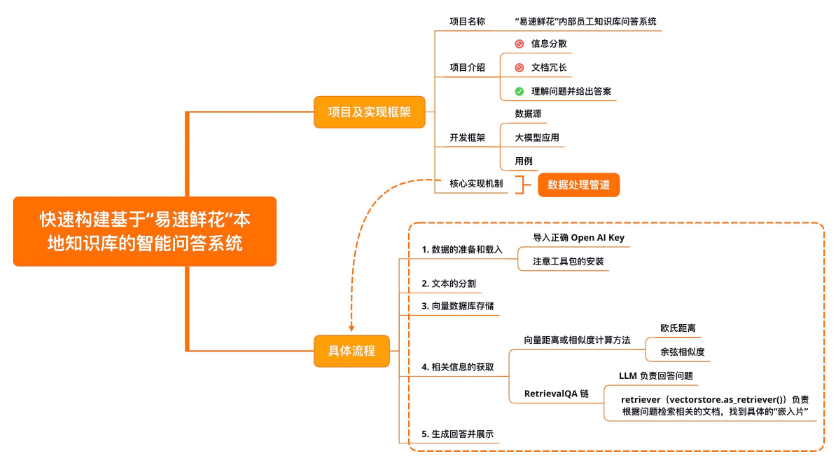
- 项目及实现框架
- 开发框架
- 核心实现机制
- 数据准备及加载
- 加载文本
- 文本的分割
- 向量数据库存储
- 文本的“嵌入”概念
- 向量数据库概念
- 相关信息获取
- RetrievalQA
- 生成回答并展示
- 示例
- 小结
Reference:LangChain 实战课
项目及实现框架
- 项目名称:“易速鲜花”内部员工知识库问答系统。
- 项目介绍:“易速鲜花”作为一个大型在线鲜花销售平台,有自己的业务流程和规范,也拥有针对员工的 SOP 手册。新员工入职培训时,会分享相关的信息。但是,这些信息分散于内部网和 HR 部门目录各处,有时不便查询;有时因为文档过于冗长,员工无法第一时间找到想要的内容;有时公司政策已更新,但是员工手头的文档还是旧版内容。
基于上述需求,我们将开发一套基于各种内部知识手册的 “Doc-QA” 系统。这个系统将充分利用 LangChain 框架,处理从员工手册中产生的各种问题。这个问答系统能够理解员工的问题,并基于最新的员工手册,给出精准的答案。
开发框架
- 开发框架:下面这张图片描述了通过 LangChain 框架实现一个知识库文档系统的整体框架。
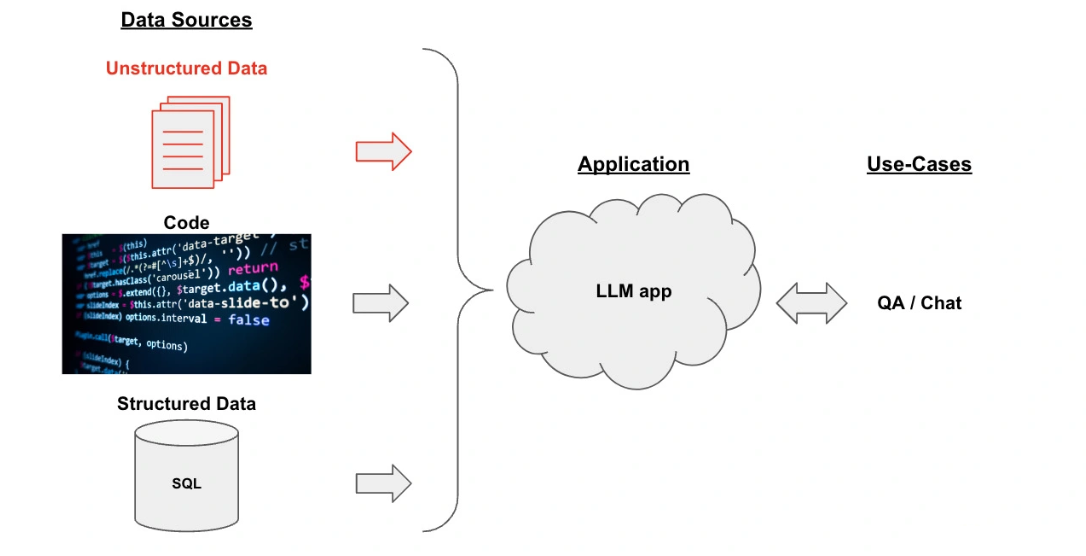
整个框架分为这样三个部分。 - 数据源(Data Sources):数据可以有很多种,包括 PDF 在内的非结构化的数据(Unstructured Data)、SQL 在内的结构化的数据(Structured Data),以及 Python、Java 之类的代码(Code)。在这个示例中,我们聚焦于对非结构化数据的处理。
- 大模型应用(Application,即 LLM App):以大模型为逻辑引擎,生成我们所需要的回答。
- 用例(Use-Cases):大模型生成的回答可以构建出 QA/ 聊天机器人等系统。
核心实现机制
核心实现机制:这个项目的核心实现机制是下图所示的数据处理管道(Pipeline)
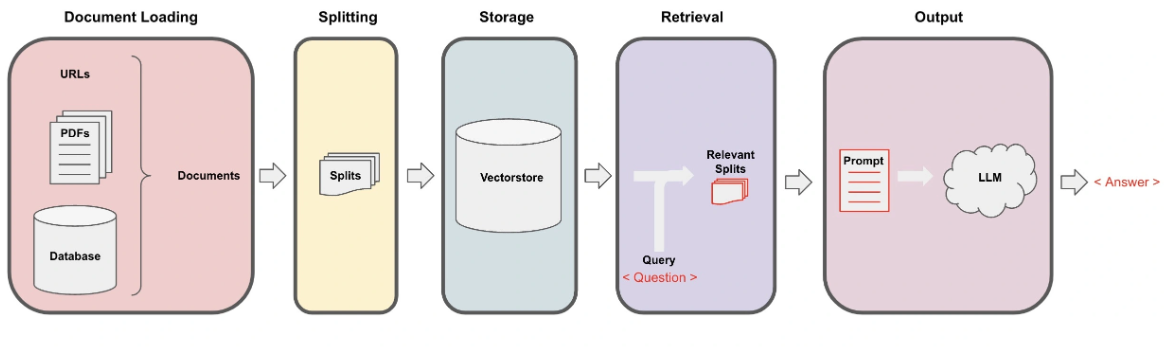
在这个管道的每一步中,LangChain 都为我们提供了相关工具,让你轻松实现基于文档的问答功能。
具体流程分为下面 5 步:
- Loading:文档加载器把 Documents 加载为以 LangChain 能够读取的形式。
- Splitting:文本分割器把 Documents 切分为指定大小的分割,我把它们称为“文档块”或者“文档片”。
- Storage:将上一步中分割好的“文档块”以“嵌入”(Embedding)的形式存储到向量数据库(Vector DB)中,形成一个个的“嵌入片”。
- Retrieval:应用程序从存储中检索分割后的文档(例如通过比较余弦相似度,找到与输入问题类似的嵌入片)。
- Output:把问题和相似的嵌入片传递给语言模型(LLM),使用包含问题和检索到的分割的提示生成答案。
上面 5 个环节的介绍都非常简单,有些概念(如嵌入、向量存储)是第一次出现,理解起来需要一些背景知识,接下来具体讲解这 5 步。
数据准备及加载
数据的准备和载入“易速鲜花”的内部资料包括 pdf、word 和 txt 格式的各种文件,可以
在此下载。
其中一个文档的示例如下:

首先用 LangChain 中的 document_loaders 来加载各种格式的文本文件。在这一步中,我们从 pdf、word 和 txt 文件中加载文本,然后将这些文本存储在一个列表中。(注意:可能需要安装 PyPDF、Docx2txt 等库)
加载文本
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'
# 1.Load 导入Document Loaders
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
# 加载Documents
base_dir = '.\OneFlower' # 文档的存放目录
documents = []
for file in os.listdir(base_dir):
# 构建完整的文件路径
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
这里我们首先导入了 OpenAI 的 API Key。
因为后面我们需要利用 Open AI 的两种不同模型做以下两件事:
- 用 OpenAI 的 Embedding 模型为文档做嵌入。
- 调用 OpenAI 的 GPT 模型来生成问答系统中的回答。
当然了,LangChain 所支持的大模型绝不仅仅是 Open AI 而已,你完全可以遵循这个框架,把 Embedding 模型和负责生成回答的语言模型都替换为其他的开源模型。
在运行上面的程序时,除了要导入正确的 Open AI Key 之外,还要注意的是工具包的安装。使用 LangChain 时,根据具体的任务,往往需要各种不同的工具包(比如上面的代码需要 PyPDF 和 Docx2txt 工具)。它们安装起来都非常简单,如果程序报错缺少某个包,只要通过 pip install 安装相关包即可。
文本的分割
接下来需要将加载的文本分割成更小的块,以便进行嵌入和向量存储。这个步骤中,我们使用 LangChain 中的 RecursiveCharacterTextSplitter 来分割文本。
# 2.Split 将Documents切分成块以便后续进行嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
现在,我们的文档被切成了一个个 200 字符左右的文档块。这一步,是为把它们存储进下面的向量数据库做准备。
向量数据库存储
我们将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。在这个例子中,我们使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入(这里需要 pip install qdrant-client)。
文本的“嵌入”概念
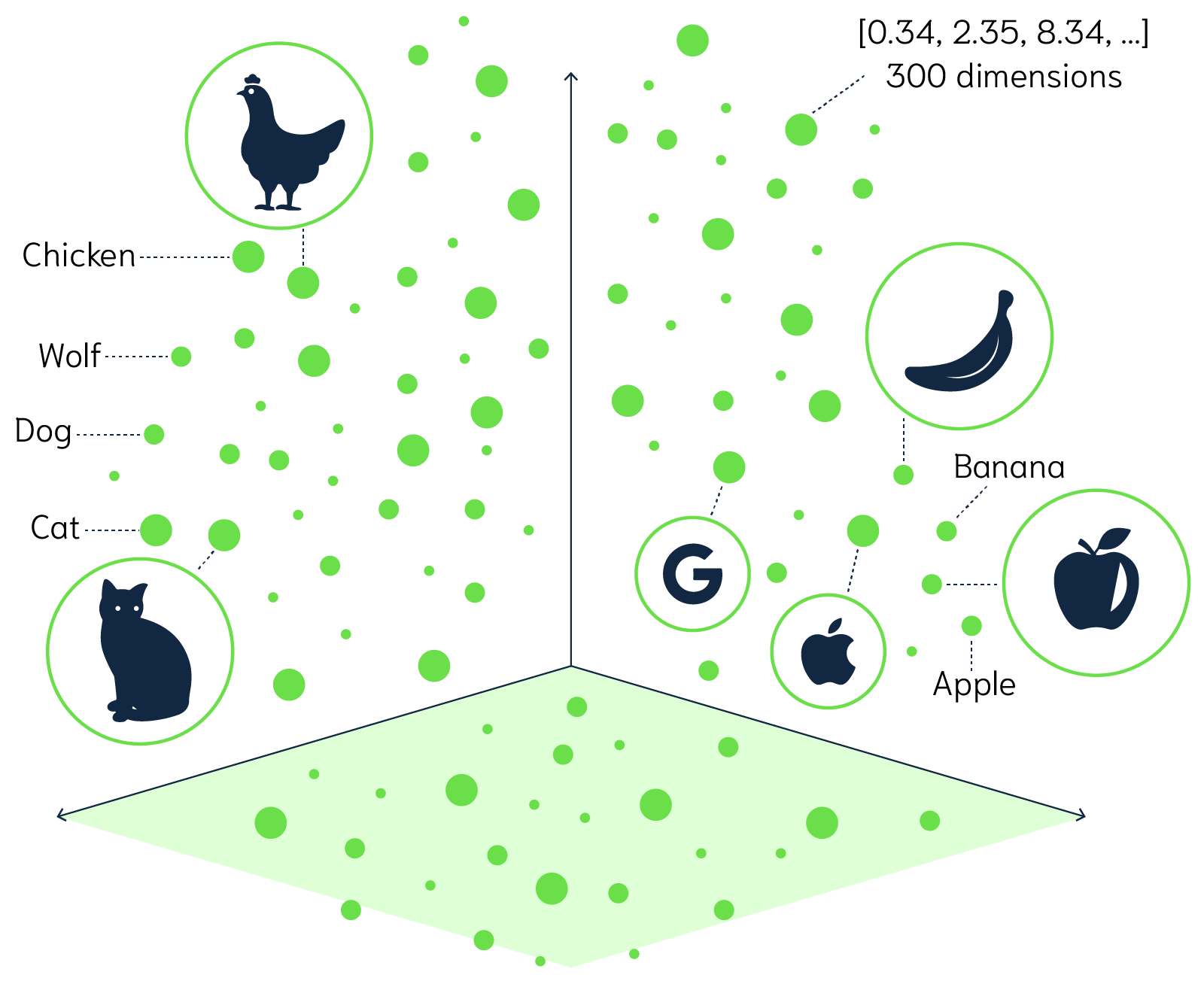
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到:
“国王” -> [1.2, 0.5, 3.1, …]“
皇帝” -> [1.3, 0.6, 2.9, …]“
苹果” -> [0.9, -1.2, 0.3, …]
从这些向量中,我们可以看到“国王”和“皇帝”这两个词的向量在某种程度上是相似的,而与“苹果”这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。
词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等 。
向量数据库概念
向量数据库,也称为矢量数据库或者向量搜索引擎,是一种专门用于存储和搜索向量形式的数据的数据库。
在众多的机器学习和人工智能应用中,尤其是自然语言处理和图像识别这类涉及大量非结构化数据的领域,将数据转化为高维度的向量是常见的处理方式。
这些向量可能拥有数百甚至数千个维度,是对复杂的非结构化数据如文本、图像的一种数学表述,从而使这些数据能被机器理解和处理。
然而,传统的关系型数据库在存储和查询如此高维度和复杂性的向量数据时,往往面临着效率和性能的问题。
因此,向量数据库被设计出来以解决这一问题,它具备高效存储和处理高维向量数据的能力,从而更好地支持涉及非结构化数据处理的人工智能应用。
向量数据库有很多种,比如 Pinecone、Chroma 和 Qdrant,有些是收费的,有些则是开源的。
LangChain 中支持很多向量数据库,这里我们选择的是开源向量数据库 Qdrant。(注意,需要安装 qdrant-client)
具体实现代码如下:
# 3.Store 将分割嵌入并存储在矢量数据库Qdrant中
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入
location=":memory:", # in-memory 存储
collection_name="my_documents",) # 指定collection_name
目前,易速鲜花的所有内部文档,都以“文档块嵌入片”的格式被存储在向量数据库里面了。那么,我们只需要查询这个向量数据库,就可以找到大体上相关的信息了。
相关信息获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息。
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
- 欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
- 余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在 -1 到 1 之间,值越接近 1,表示两个向量的方向越相似。
这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景。
什么时候选择欧式距离,什么时候选择余弦相似度呢?
简单来说,关心数量等大小差异时用欧氏距离,关心文本等语义差异时用余弦相似度。
具体来说,欧氏距离度量的是绝对距离,它能很好地反映出向量的绝对差异。当我们关心数据的绝对大小,例如在物品推荐系统中,用户的购买量可能反映他们的偏好强度,此时可以考虑使用欧氏距离。同样,在数据集中各个向量的大小相似,且数据分布大致均匀时,使用欧氏距离也比较适合。
余弦相似度度量的是方向的相似性,它更关心的是两个向量的角度差异,而不是它们的大小差异。在处理文本数据或者其他高维稀疏数据的时候,余弦相似度特别有用。比如在信息检索和文本分类等任务中,文本数据往往被表示为高维的词向量,词向量的方向更能反映其语义相似性,此时可以使用余弦相似度。
RetrievalQA
在这里,我们正在处理的是文本数据,目标是建立一个问答系统,需要从语义上理解和比较问题可能的答案。因此,建议使用余弦相似度作为度量标准。通过比较问题和答案向量在语义空间中的方向,可以找到与提出的问题最匹配的答案。
在这一步的代码部分,我们会创建一个聊天模型。然后需要创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在 RetrievalQA 链中有下面两大重要组成部分:
- LLM 是大模型,负责回答问题。
- retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的“嵌入片”。这些“嵌入片”对应的“文档块”就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为从互联网信息中训练而来的大模型不可能拥有“易速鲜花”作为一个私营企业的内部知识。
具体代码如下:
# 4. Retrieval 准备模型和Retrieval链
import logging # 导入Logging工具
from langchain.chat_models import ChatOpenAI # ChatOpenAI模型
from langchain.retrievers.multi_query import MultiQueryRetriever # MultiQueryRetriever工具
from langchain.chains import RetrievalQA # RetrievalQA链
# 设置Logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
# 实例化一个大模型工具 - OpenAI的GPT-3.5
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
# 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
现在我们已经为后续的步骤做好了准备,下一步就是接收来自系统用户的具体问题,并根据问题检索信息,生成回答。
生成回答并展示
这一步是问答系统应用的主要 UI 交互部分,这里会创建一个 Flask 应用(需要安装 Flask 包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
# 5. Output 问答系统的UI实现
from flask import Flask, request, render_template
app = Flask(__name__) # Flask APP
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
# 接收用户输入作为问题
question = request.form.get('question')
# RetrievalQA链 - 读入问题,生成答案
result = qa_chain({"query": question})
# 把大模型的回答结果返回网页进行渲染
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)
相关 HTML 网页的关键代码如下:
<body>
<div class="container">
<div class="header">
<h1>易速鲜花内部问答系统</h1>
<img src="{{ url_for('static', filename='flower.png') }}" alt="flower logo" width="200">
</div>
<form method="POST">
<label for="question">Enter your question:</label><br>
<input type="text" id="question" name="question"><br>
<input type="submit" value="Submit">
</form>
{% if result is defined %}
<h2>Answer</h2>
<p>{{ result.result }}</p>
{% endif %}
</div>
</body>
示例

提问:仪容仪表规范的发型要求是什么?
回答:发型要求包括以下几点: - 男员工的头发长度应适中,前不过眉、后不过领、侧不过耳,呈现自然色。 - 女员工的头发长度不可过肩,过肩发需束起来,不可散落,并用深色且式样简洁、大小不超过十公分的头饰,呈现自然色。

小结
如下图所示,我们先把本地知识切片后做 Embedding,存储到向量数据库中,然后把用户的输入和从向量数据库中检索到的本地知识传递给大模型,最终生成所想要的回答。
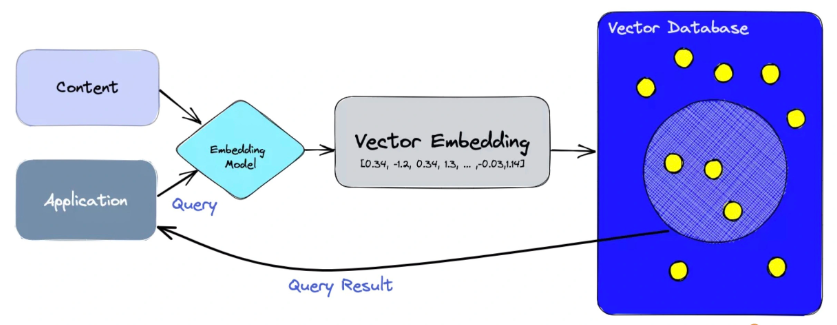
LangChain+LLM 的配置就是使原本复杂的东西变得特别简单,特别易于操作。而这个任务,在大模型和 LangChain 出现之前,要实现起来可不是这么简单的。