参考文章:GPT系列模型技术路径演进-CSDN博客
这篇文章讲了之前称霸NLP领域的预训练模型bert,它是基于预训练理念,采用完形填空和下一句预测任务2个预训练任务完成特征的提取。当时很多的特定领域的NLP任务(如情感分类,信息抽取,问答等)都是采用bert加上领域数据微调解决。
【期末向】“我也曾霸榜各类NLP任务”-bert详解-CSDN博客文章浏览阅读208次,点赞4次,收藏3次。首先我们要了解一下什么是预训练模型,举个例子,假设我们有大量的维基百科数据,那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做文本相似度计算,那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整。NSP属于二分类任务,在此任务中,我们输入两个句子,B有50%的可能是A的下一句,也有50%的可能是来自语料库的随机句子,预测B是不是A的下一句。即对于给定的输入序列,我们随机屏蔽15%的单词,然后训练模型去预测这些屏蔽的单词。https://blog.csdn.net/weixin_62588253/article/details/135002295?spm=1001.2014.3001.5501但是2022年底,随着ChatGPT的兴起,大模型开始全面替代各种特定领域的NLP任务。下面就讲讲ChatGPT的发展史以及对NLP带来的影响。
(1)GPT及其结构
ChatGPT(Chat Generative Pre-trained Transformer)系列,最早由OpenAI(也叫CloseAI,开玩笑)于2018年提出第一版GPT,也是预训练语言模型。GPT的任务最初就是从网上爬取完整的句子数据,用于训练预测给定上下文信息后的下一个单词。仅仅凭借这一预训练方式和未标注的数据集GPT就可以完成对话任务,但是效果并不好 。
GPT与bert不同,bert采用的是transformer中的encoder结构;而GPT采用的则是decoder结构,如下图所示:

(2)GPT-2
2019年OpenAI又提出了GPT-2,其目标旨在训练一个泛化能力更强的词向量模型,但是它并没有对GPT的网络进行过多的结构的创新与设计,而是采用更多的网络参数和更大的数据集。但是它提出了一个后来成为大模型称霸NLP的理念:zero-shot即零少样本学习。它认为可以将预训练好的模型直接应用到下游任务,而不用根据特定领域的标注数据再次微调,只需要模型根据给定的指令(prompt或instruction)来理解任务。OpenAI作者认为,当一个语言模型的容量足够大时,它就能足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务,这个思想也是提示学习(Prompt Learning)的前身。
(3)GPT-3
2020年,GPT-3发布。相比之前的GPT,GPT-3的显著特点是参数很多,是一个巨型模型,参数量高达1750亿参数量。与此同时,GPT-3还验证了GPT-2中提出的zero-shot的理念。所谓的zero-shot,就是零样本学习,它是直接应用到下游任务的,不会改变模型的参数。具体想法是利用过去的知识(预训练获得的信息),在脑海中推理出新的知识,从而能在没有微调的情况下完成原来需要利用特殊领域数据微调才能完成的下游任务。值得一提的是,这种理念可以用在各种领域,而非局限在NLP。

除了zero-shot,还有one-shot和few-shot。one-shot是指在预测时将一个例子也作为输入输入模型;few-shot是指在预测时加上几个例子作为输入。

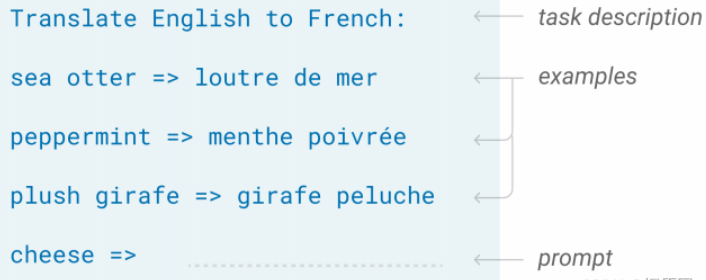
(4)ChatGPT
预训练模型自诞生之始,一个备受诟病的问题就是预训练模型的偏见性。因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,对比完全由人工规则控制的专家系统来说,预训练模型就像一个黑盒子。没有人能够保证预训练模型不会生成一些包含种族歧视,性别歧视等危险内容,因为它的几十GB甚至几十TB的训练数据里几乎肯定包含类似的训练样本。这也就是InstructGPT和ChatGPT的提出动机,论文中用3H概括了它们的优化目标:
- 有用的(Helpful)
- 可信的(Honest)
- 无害的(Harmless)
因此在2021和2022年OPenAI分别发表InstructCPT和ChatGPT,并提出了全新的训练步骤,这也是ChatGPT与bert等传统预训练语言模型。
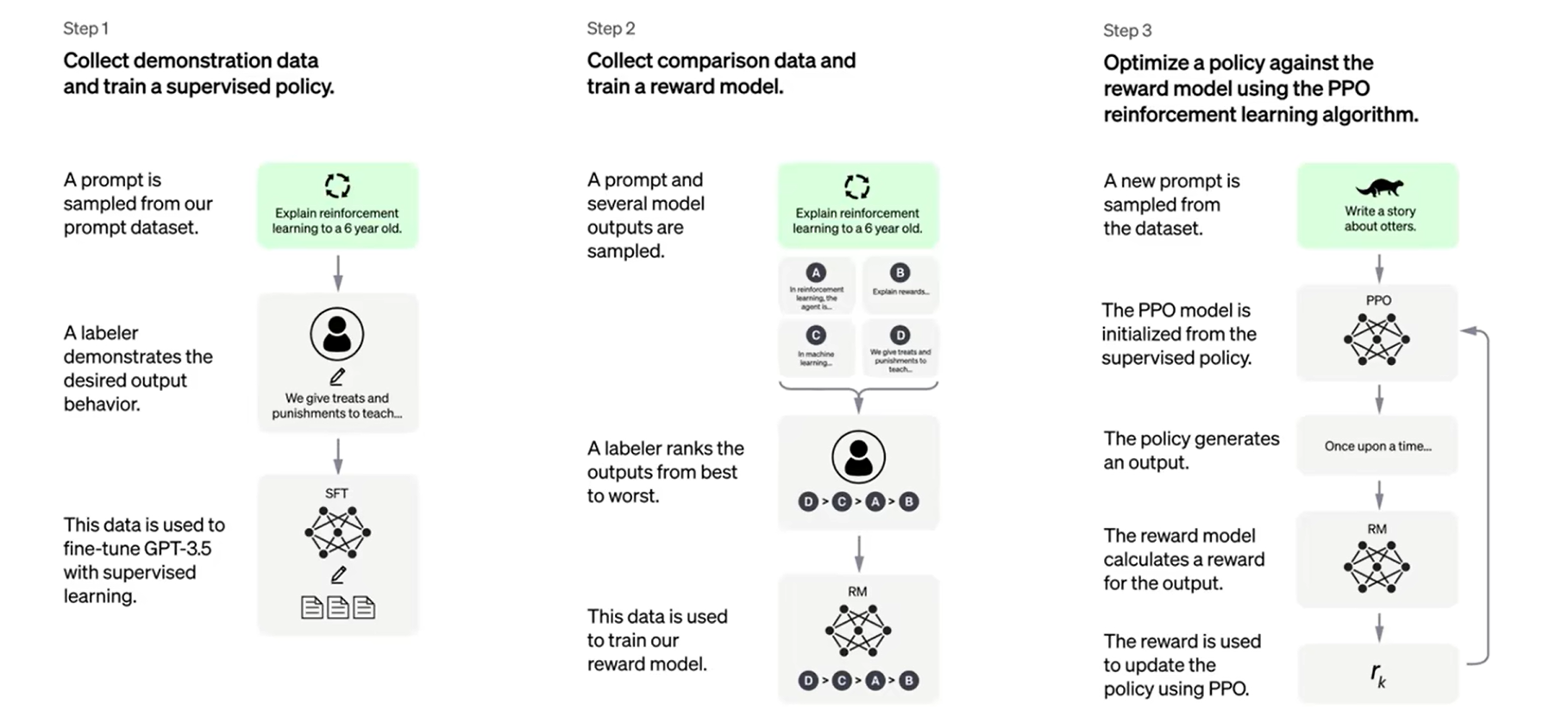
第一步-预训练。当然是预训练步骤(上图没有展示出来),利用大量的网上爬取的数据做无监督的预训练,任务应该还是预测下一个字。
第二步-微调(SFT)。利用人工标注的数据做微调,注意这里的微调并非针对特定的下游任务。而是针对预训练过程中部分数据存在的偏见等问题,由人类标注一些符合人类伦理道德、喜好的数据对其进行纠正。并且这里并不需要太多的人工标注的数据,是因为模型本身预训练已经知道了正确答案,只是受到了脏数据的影响不一定能够生成符合人类需要的数据。因此只需要一部分数据来告诉那些数据符合人类偏好即可。
第三步-训练打分模型(RM)。这里分2步,第一步因为ChatGPT开放使用所以可以收集用户与ChatGPT之间的对话数据。然后由人工对这些对话数据进行打分得到一个新的数据集。然后利用这个数据集来训练一个打分模型RM,它可以对ChatGPT不同的回复进行打分,用于模拟人类的打分。
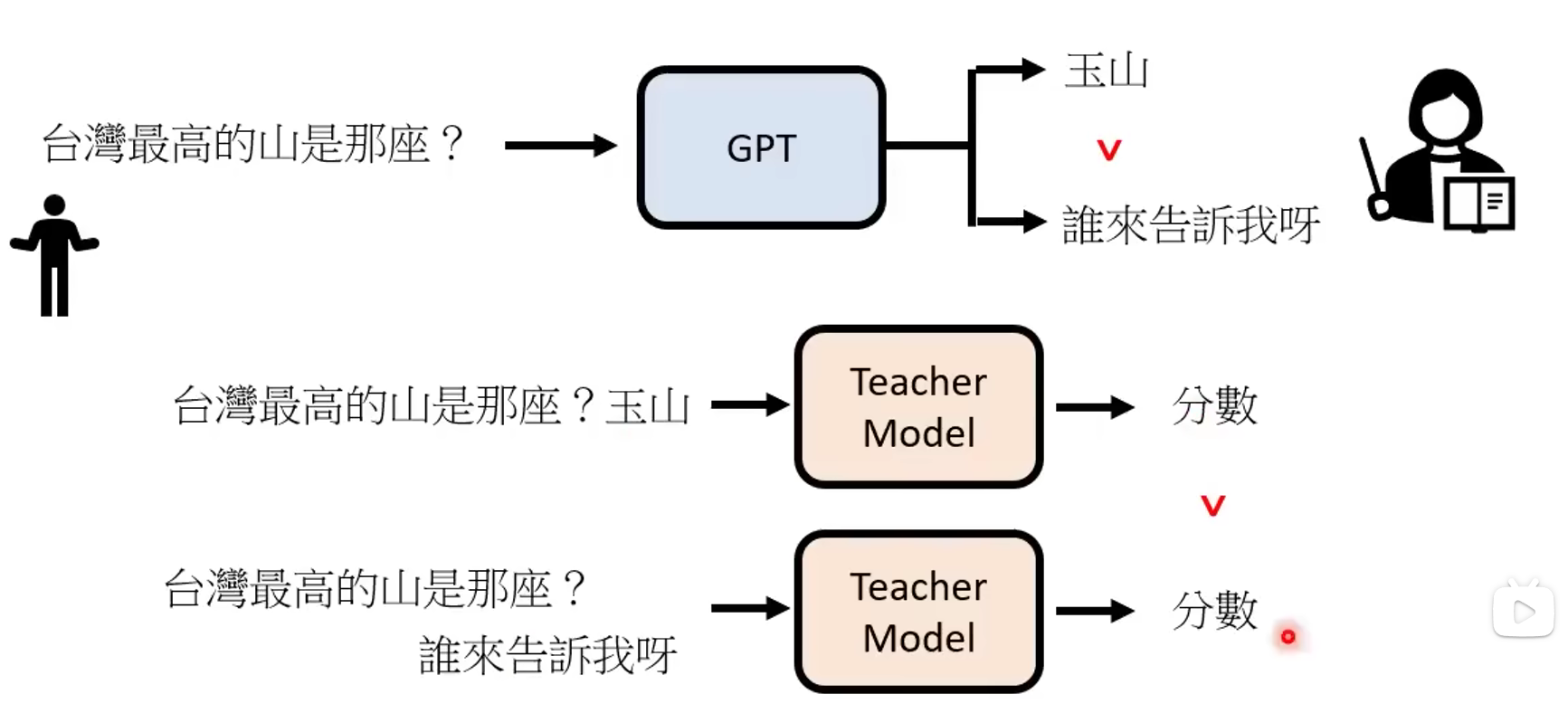
第四步-强化学习(RLFM,Reinforcement Learning from Human Feedback) 。这里是利用强化学习PPO算法,通过前面RM模型给出的分数来调整ChatGPT的参数,使得其得分更高,也就是ChatGPT的回答更符合人类的需求。
![[Vulnhub靶机] DC-1](https://img-blog.csdnimg.cn/direct/4f68c8fa81654f699b12466cde86dfd4.png)