note
- 一些大模型的评估模型:
- 多轮:MTBench
- 关注评估:agent bench
- 长文本评估:longbench,longeval
- 工具调用评估:toolbench
- 安全评估:cvalue,safetyprompt等
文章目录
- note
- 常见评测benchmark
- rouge
- factool
- MMLU
- C-Eval
- GSM8K
- BBH
- zhenbench case
- 其他人工评估指标
- 相关排行榜
- Reference
常见评测benchmark
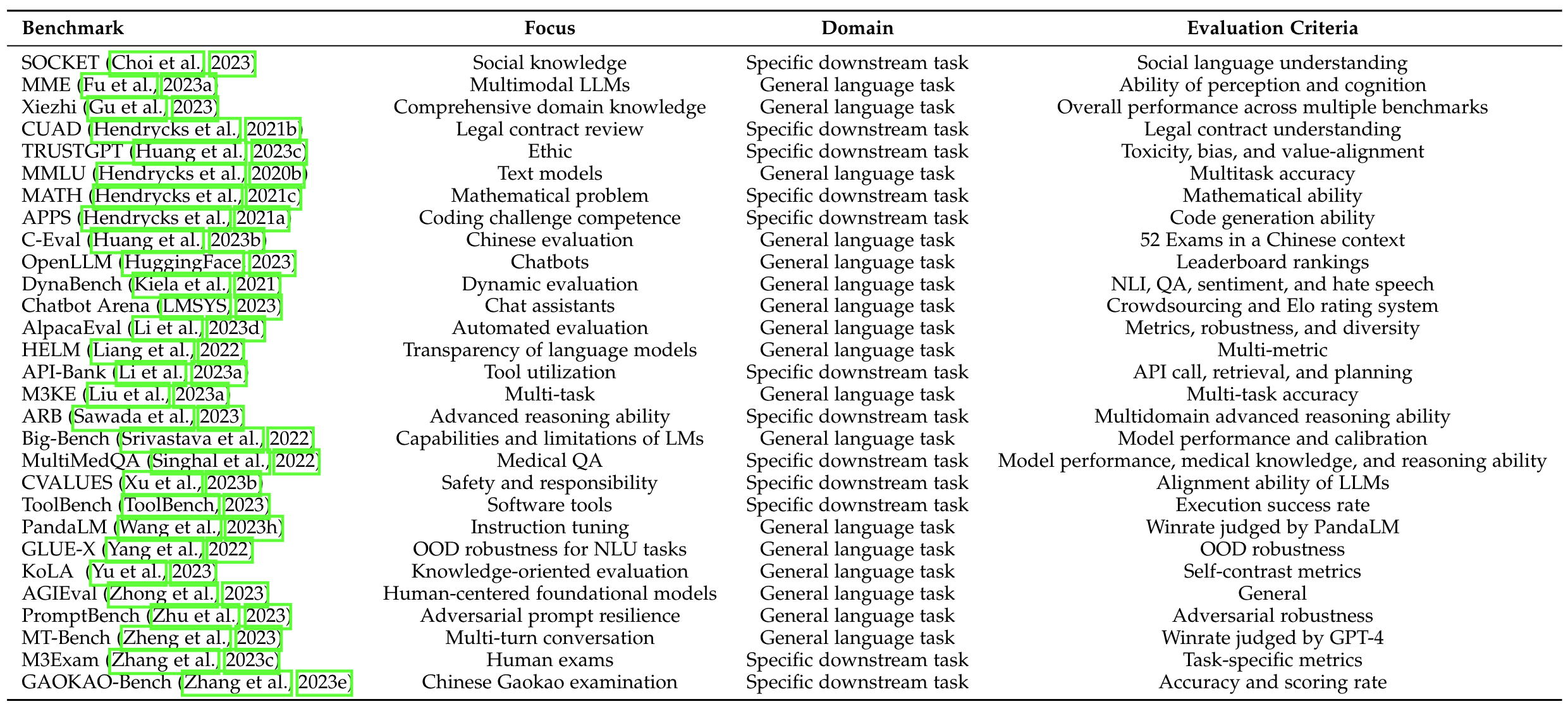
图源自《A Survey on Evaluation of Large Language Models》
rouge
ROUGE-1、ROUGE-2、ROUGE-L和 BERTScore
- ROUGE指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算得到得分。
- 一般看f值,f是取了f和r的调和平均值
- 下面的
rouge包不能直接使用中文文本,需要分词后使用,如果文本长度不长时可以手动修改,如“你好吗”改为“你 好 吗”
from rouge import Rouge
hypothesis = "the #### transcript is a written version of each day 's cnn student news program use this transcript to he lp students with reading comprehension and vocabulary use the weekly newsquiz to test your knowledge of storie s you saw on cnn student news"
reference = "this page includes the show transcript use the transcript to help students with reading comprehension and vocabulary at the bottom of the page , comment for a chance to be mentioned on cnn student news . you must be a teac her or a student age # # or older to request a mention on the cnn student news roll call . the weekly newsquiz tests students ' knowledge of even ts in the news"
rouger = Rouge()
scores = rouger.get_scores(hypothesis, reference)
[
{
"rouge-1": {
"f": 0.4786324739396596,
"p": 0.6363636363636364,
"r": 0.3835616438356164
},
"rouge-2": {
"f": 0.2608695605353498,
"p": 0.3488372093023256,
"r": 0.20833333333333334
},
"rouge-l": {
"f": 0.44705881864636676,
"p": 0.5277777777777778,
"r": 0.3877551020408163
}
}
]
factool
https://github.com/GAIR-NLP/factool
以下的几个指标都是chatglm2使用到的评估指标:
MMLU
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试
C-Eval
如果是做题问答,可以用Ceval指标,chatglm2-6b项目中就有代码
我们选取了部分中英文典型数据集进行了评测,以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。在 evaluation 中提供了在 C-Eval 上进行测评的脚本。
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试
GSM8K
| Model | Accuracy | Accuracy (Chinese)* |
|---|---|---|
| ChatGLM-6B | 4.82 | 5.85 |
| ChatGLM2-6B (base) | 32.37 | 28.95 |
| ChatGLM2-6B | 28.05 | 20.45 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
* 我们使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对
BBH
| Model | Accuracy |
|---|---|
| ChatGLM-6B | 18.73 |
| ChatGLM2-6B (base) | 33.68 |
| ChatGLM2-6B | 30.00 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
zhenbench case
https://github.com/zhenbench/zhenbench
其他人工评估指标
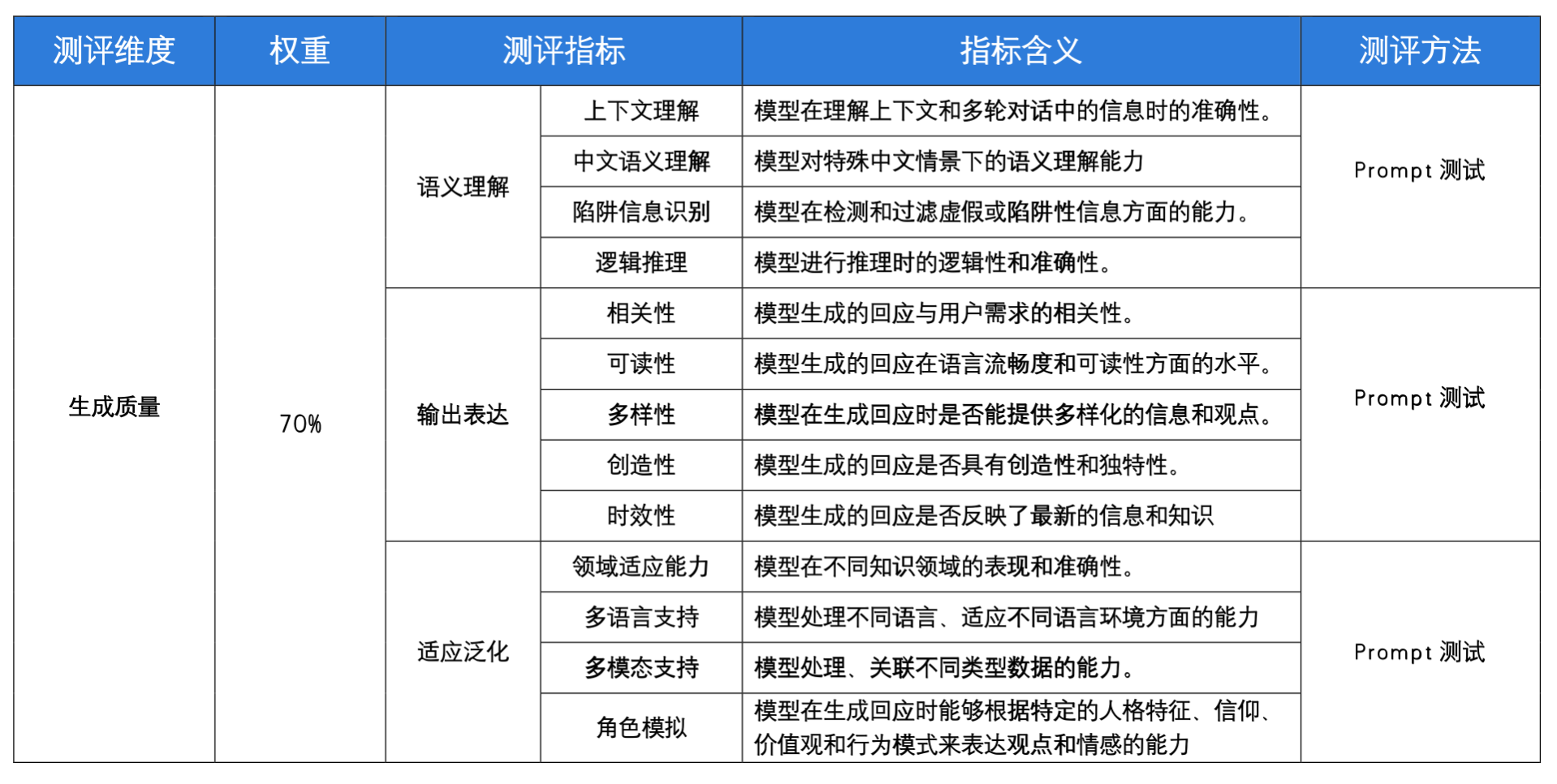
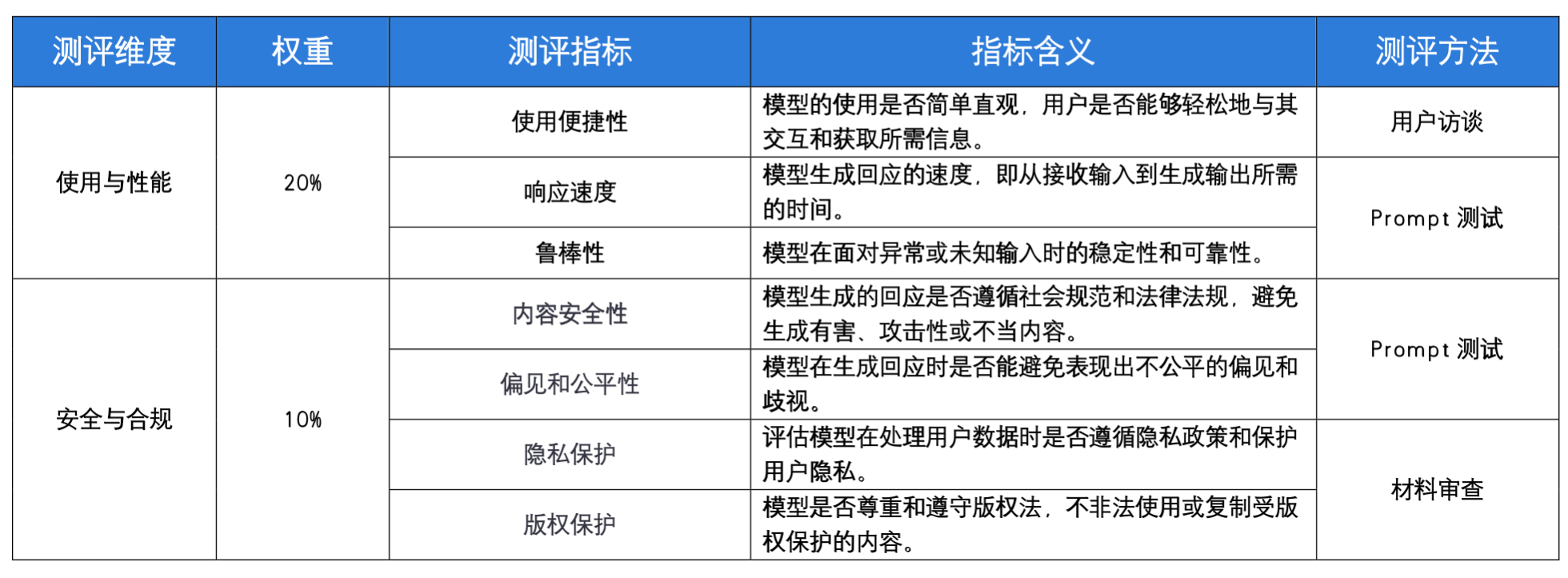
注:“领域适应能力”测试中的知识领域包括,代码编程、数学计算、创意写作、舆情分析、医学咨询、历史知识、法律信息、科学解释、翻译。
测评结果:
 总得分率=生成质量70%+使用与性能20%+安全与合规*10%,评估截止日期为2023年6月30日。
总得分率=生成质量70%+使用与性能20%+安全与合规*10%,评估截止日期为2023年6月30日。
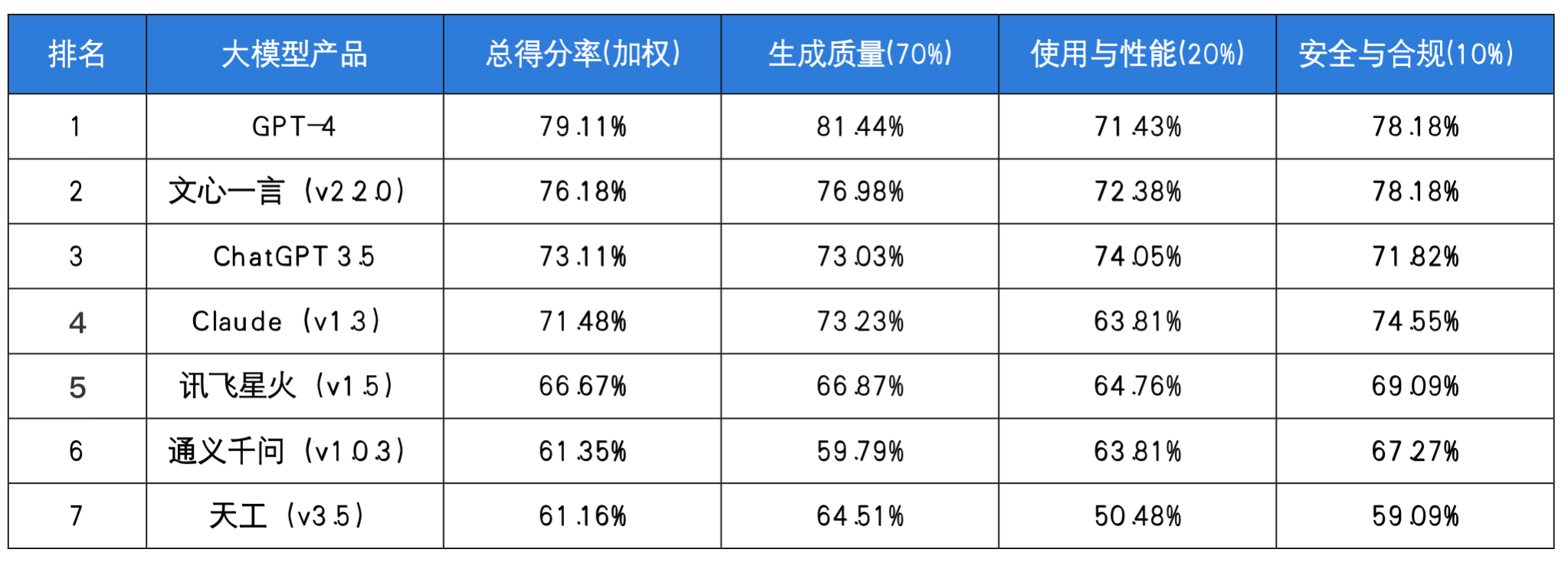
评估后的大模型选择:
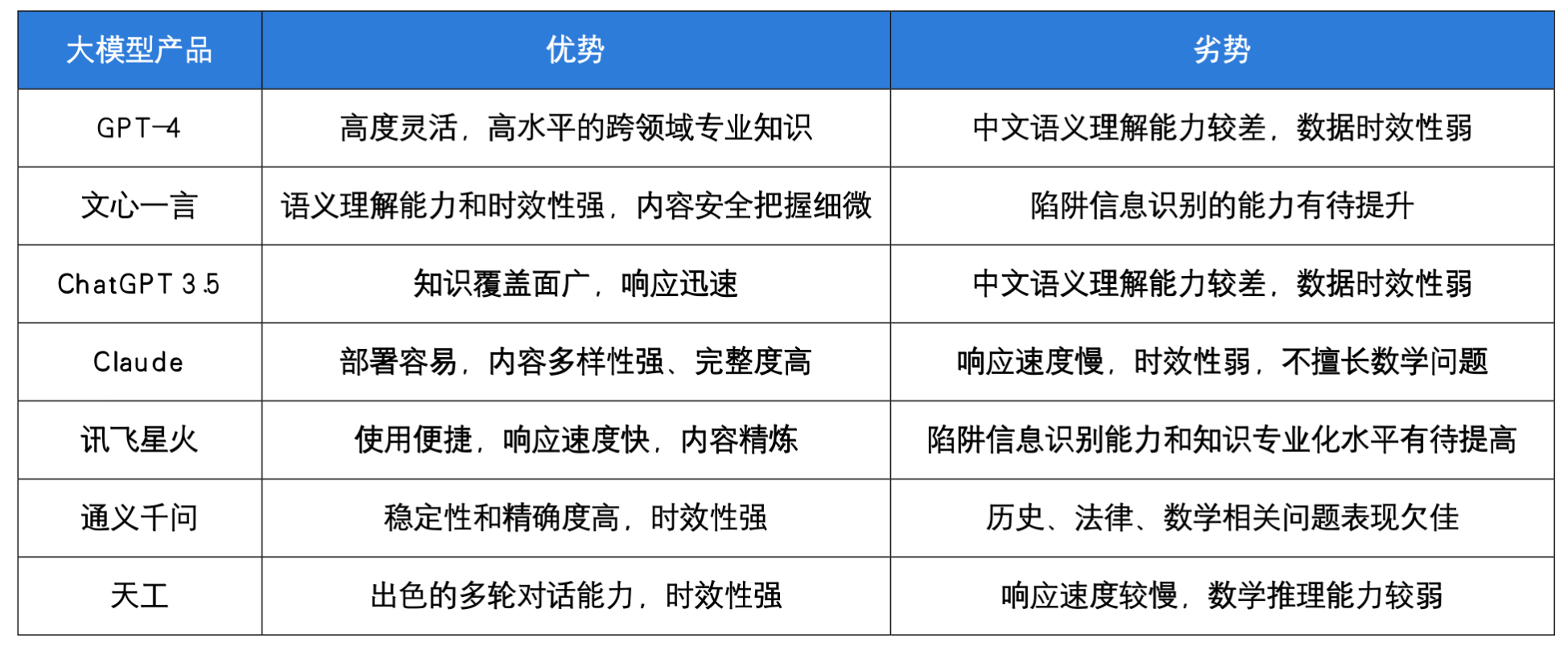
相关排行榜
LMSYS、c-Eval、SuperCLUElyb、PubMedQA排行榜
Reference
[1] ROUGE: A Package for Automatic Evaluation of Summaries
[2] NLP评估指标之ROUGE
[3] 大模型评测综述:A Survey on Evaluation of Large Language Models
[4] 目前大语言模型的评测基准有哪些-某乎